


Reinforcement Learning IT Powerpoint Presentation Slides





Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


Reinforcement learning provider Company is a firm whose algorithms have shown remarkable accuracy in forecasting a companys capacity to repay its debts and the likelihood of dilution and the danger of default. Check out our professionally designed PowerPoint presentation that briefly explains the reinforcement learning provider company, reasons to use it, and an introduction to reinforcement learning, including its features, key terminology, benefits, and implementation challenges. In this Reinforcement Learning PowerPoint Presentation, we have covered the elements of RL, such as policy, reward signal, value function, and model. In addition, this Reinforcement Learning in ML deck contains the working of reinforcement learning, its workflow, approaches, and learning models such as the Markov Decision Process, Q-Learning, SARSA, etc. Also, the Reinforcement Learning PPT incorporates examples of RL and its applications in different industries, such as gaming, marketing, image processing, robotics, healthcare, broadcast journalism, and manufacturing. Furthermore, it comprises a relationship between reinforcement, supervised, unsupervised, deep, and machine learning. Lastly, the Reinforcement Learning PowerPoint presentation caters to a training program, pricing details for RL projects, timeline, roadmap, and performance tracking dashboard for the reinforcement learning model. Get access now.
People who downloaded this PowerPoint presentation also viewed the following :
Content of this Powerpoint Presentation
Slide 1: This slide introduces Reinforcement Learning. Commence by stating Your Company Name.
Slide 2: This slide depicts the Agenda of the presentation.
Slide 3: This slide reveals the Table of contents.
Slide 4: This is yet another slide continuing the Table of contents.
Slide 5: This slide includes the Title for the Topics to be covered in the next template.
Slide 6: This slide represents the overview of the reinforcement learning provider company.
Slide 7: This slide depicts the reasons for clients choosing the reinforcement learning provider company for RL services.
Slide 8: This slide highlights the Heading for the Contents to be covered next.
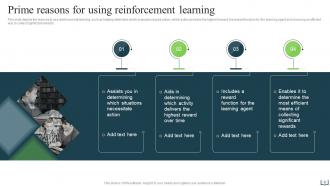
Slide 9: This slide states the prime reasons to use reinforcement learning.
Slide 10: This slide potrays the Title for the Ideas to be discussed further.
Slide 11: This slide gives an overview of reinforcement learning, a feedback-based machine learning technique.
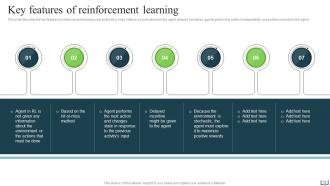
Slide 12: This slide describes the key features of reinforcement learning such as the hit or miss method, delayed incentives, etc.
Slide 13: This slide depicts the terms used in reinforcement learning, including agent, environment, etc.
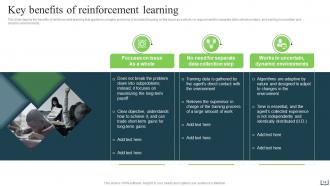
Slide 14: This slide presents the Key benefits of reinforcement learning that applies to complex problems.
Slide 15: This slide represents the challenges with reinforcement learning that make RL adoption slow in real-world situations.
Slide 16: This slide incorporates the Heading for the Topics to be covered next.
Slide 17: This slide represents an overview of the policy element of reinforcement learning, which defines the behavior of the agent.
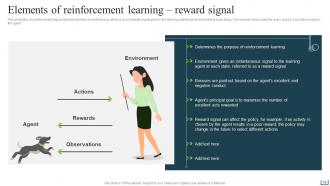
Slide 18: This slide talks about the reward signal element of reinforcement learning.
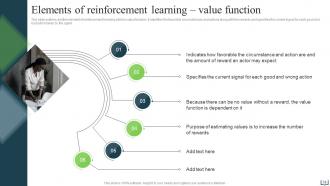
Slide 19: This slide outlines another element of reinforcement learning which is value function.
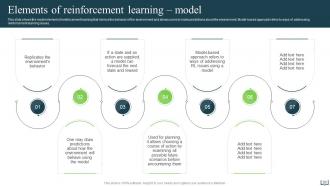
Slide 20: This slide shows the model element of reinforcement learning.
Slide 21: This slide exhibits the Title for the Topics to be covered further.
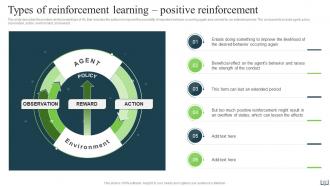
Slide 22: This slide describes the positive reinforcement type of Reinforcement Learning.
Slide 23: This slide represents the negative reinforcement that strengthens the agent's behavior to avoid wrong actions.
Slide 24: This slide exhibits the Heading for the Contents to be discussed further.
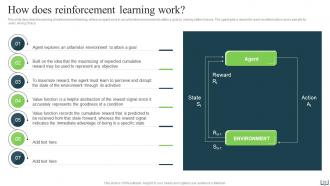
Slide 25: This slide deals with the working of reinforcement learning, where an agent work in an unfamiliar environment to attain a goal by making better choices.
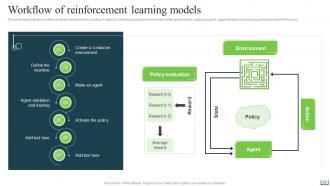
Slide 26: This slide presents the workflow of reinforcement learning models.
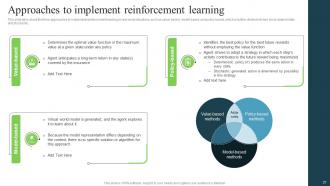
Slide 27: This slide talks about the three approaches to implement reinforcement learning in real-world situations.
Slide 28: This slide incorporates the Title for the Topics to be covered further.
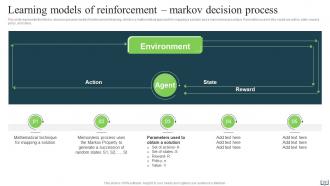
Slide 29: This slide represents the Markov decision process model of reinforcement learning.
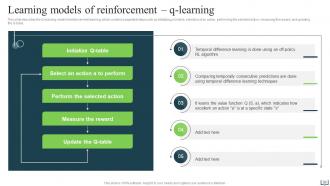
Slide 30: This slide describes the Q-learning model of reinforcement learning, which contains numerous sequential steps.
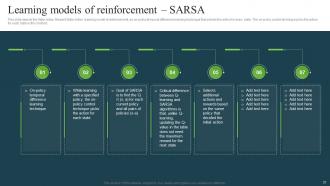
Slide 31: This slide depicts the State Action Reward State Action learning model of reinforcement.
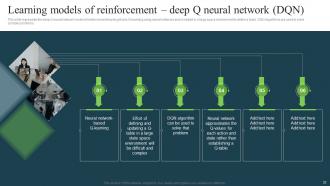
Slide 32: This slide represents the deep Q neural network model of reinforcement learning that is helpful in a large space environment to define a table.
Slide 33: This slide contains the Heading for the Contents to be discussed further.
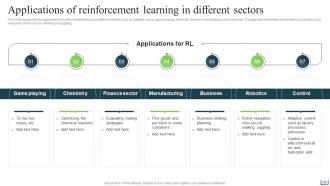
Slide 34: This slide reveals the applications of reinforcement learning in different sectors.
Slide 35: This slide talks about how reinforcement learning can enhance gamers' gaming experience by providing incredible performance through prediction models.
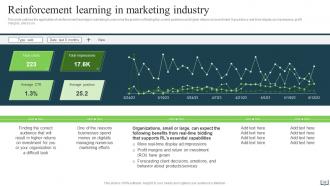
Slide 36: This slide outlines the application of reinforcement learning in marketing to overcome the problem of finding the correct audience and higher returns on investment.
Slide 37: This slide represents reinforcement learning in image processing, including various steps.
Slide 38: This slide outlines how reinforcement learning is used to train robots to perform their jobs like humans.
Slide 39: This slide displays the application of reinforcement learning in healthcare department.
Slide 40: This slide talks about how reinforcement learning can improve broadcast journalism.
Slide 41: This slide describes the application of reinforcement learning in the manufacturing field.
Slide 42: This slide describes examples of reinforcement learning such as robotics, AlphaGo, and autonomous driving.
Slide 43: This slide includes the Title for the Topics to be covered further.
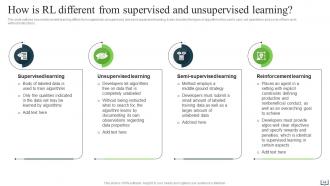
Slide 44: This slide outlines how reinforcement learning differs from supervised, unsupervised, and semi-supervised learning.
Slide 45: This slide talks about the comparison between reinforcement learning and supervised learning based on various parameters.
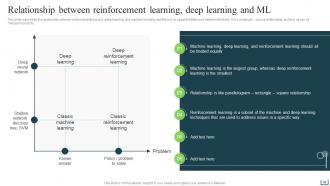
Slide 46: This slide represents the relationship between reinforcement learning, deep learning, and machine learning, and states no apparent difference between the three.
Slide 47: This slide covers the Heading for the Contents to be discussed further.
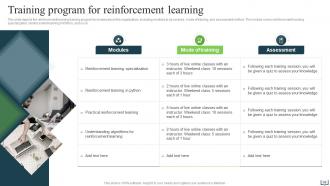
Slide 48: This slide depicts the reinforcement learning training program for employees in the organization.
Slide 49: This slide elucidates the Title for the Ideas to be discussed in the next template.
Slide 50: This slide represents the pricing for building reinforcement learning models.
Slide 51: This slide contains the Title for the Topics to be discussed further.
Slide 52: This slide depicts the timeline for the reinforcement learning project.
Slide 53: This slide exhibits the Title for the Contenst to be covered further.
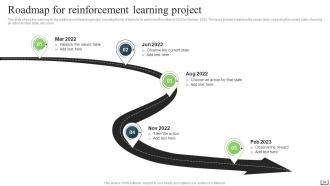
Slide 54: This slide illustrates the roadmap for the reinforcement learning project.
Slide 55: This slide includes the Title for the Topics to be covered next.
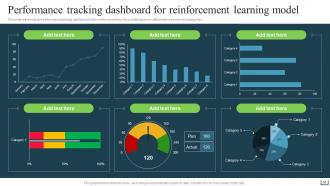
Slide 56: This slide represents the performance tracking dashboard for the reinforcement learning model based on different time frames and categories.
Slide 57: This is the Icons slide reinforcement learning containing all the Icons used in the plan.
Slide 58: This slide reveals the Additional Company information.
Slide 59: This is Our mission slide. State your Organization's mission in this one.
Slide 60: This is About us slide depicting the Organization's information.
Slide 61: This slide exhibits the 30 60 90 days plan for efficient planning.
Slide 62: This slde shows the Magnifying glass for minute details.
Slide 63: This is the Venn Diagram slide for relevant Company information.
Slide 64: This slide includes the Important notes for reminders and deadlines.
Slide 65: This is the Puzzle slide with related imagery.
Slide 66: This is the Thank you slide for acknowledgemnt.
Reinforcement Learning IT Powerpoint Presentation Slides with all 71 slides:
Use our Reinforcement Learning IT Powerpoint Presentation Slides to effectively help you save your valuable time. They are readymade to fit into any presentation structure.











































FAQs for Reinforcement Learning IT
So RL is basically trial and error on steroids. The algorithm tries stuff, gets rewards or punishments, then figures out what works best over time. It's different from regular machine learning because you're not giving it the "right" answers upfront - just letting it mess around and learn from consequences. The whole thing revolves around an agent doing actions in some environment while chasing rewards. Honestly, games are probably your best bet for starting out since the reward systems are super obvious. Way easier to understand when you can actually see what's happening, you know?
Add rewards that nudge your agent toward the main goal without screwing up the optimal solution. It's like leaving breadcrumbs - give positive feedback when it gets closer or finishes subtasks. Just make sure they're "potential-based" so you don't break the underlying problem. I've watched people get way too fancy and accidentally train their agent to exploit the reward system instead of actually solving anything. Distance-based rewards work great to start with. Then you can layer on more complex stuff once you see what clicks.
So Q-learning is basically smart trial-and-error with a good memory. Your algorithm tries different actions in various situations and remembers what worked based on the rewards it gets back. The cool part? It doesn't need to understand how the environment actually works - just learns from experience. What's really useful is how it deals with delayed consequences. Like, sometimes the best move doesn't pay off immediately, but Q-learning figures that out over time. I've seen people use it for everything from teaching AI to play games to optimizing supply chains. Pretty versatile stuff, honestly.
So deep RL is basically just slapping neural networks onto regular reinforcement learning to handle crazy complex environments. Traditional RL breaks down when you can't store every state in a table anymore - like, imagine trying to memorize every possible Atari screen configuration, that's insane. The neural networks learn to estimate values or policies from raw pixels instead. They generalize across similar situations they haven't seen before, which is pretty cool. DQN was the big breakthrough here - it doesn't memorize every pixel combo, just learns useful patterns. Honestly, start with DQN on something simple if you're diving in.
Honestly, the data requirements are brutal - RL is ridiculously sample inefficient. Safety's another huge headache when you move from sim to real environments. And don't get me started on reward engineering... trying to mathematically define "success" will make you question your life choices lol. Domain randomization helps close that sim-to-real gap though. Transfer learning from simpler tasks works well too. Safe exploration techniques like constrained policy optimization are pretty much essential if you don't want your robot destroying everything. My take? Start stupidly simple with toy problems first. Complex real-world stuff can wait.
So your agent needs to balance trying new stuff (exploration) vs sticking with what already works (exploitation). Too much exploitation? You get stuck with mediocre strategies. Go overboard on exploration and you'll never actually use the good moves you discover. Epsilon-greedy is super simple to code - just explore randomly like 10% of the time. UCB and Thompson sampling are fancier options but honestly, start with epsilon-greedy first. Pro tip: gradually reduce your exploration rate as training goes on. Your agent gets smarter so it doesn't need to experiment as much later.
Environments are everything for RL agents, honestly. They set up what your agent can do, the feedback it receives, and how it learns. Picture teaching someone to drive - road conditions and traffic totally shape how they pick up skills. Your environment controls state space, actions, rewards, and transitions that drive learning. Sparse rewards will train your agent way differently than dense feedback does. Oh and when training isn't working? Check if your environment is actually teaching what you want. I've wasted hours debugging code when the real issue was just poorly designed rewards.
So basically you've got multiple agents all learning at once in the same space, each chasing their own rewards. The annoying thing is your environment keeps shifting because everyone else is updating their strategies too - kinda like learning poker while everyone at the table is also getting smarter. Traditional RL just can't handle this mess. You'll run into convergence problems, plus it's super hard to figure out which agent actually caused what result. Oh, and don't even get me started on getting them to coordinate properly. Honestly, I'd stick with cooperative setups first before diving into competitive stuff.
So there's a bunch of stuff that actually works well for this. Transfer learning is probably your best bet - train on easier tasks first, then move to the harder one. Domain randomization is solid too, basically you mess with the environment parameters during training so it sees way more scenarios. Meta-learning is honestly pretty neat because it teaches the model to adapt fast to new situations. Oh and multi-task learning where you train on multiple related things at once. The whole point is getting your model exposed to diverse experiences while training. Think of it more like building a Swiss Army knife instead of just memorizing one trick.
So TD learning is like the foundation for most RL stuff - you don't have to wait for whole episodes to finish before learning something. You just update your predictions step by step using the gap between what you expected vs what actually happened (plus your guess about future rewards). Honestly took me forever to wrap my head around it at first, but once you get it, everything else makes way more sense. Q-learning, actor-critic methods - they're all built on this idea of learning incrementally from experience. Start with TD(0) implementation. Trust me, it'll save you headaches later when you hit Deep Q-Networks.
Okay so basically - model-based RL learns how the environment works first, then plans ahead. Super sample efficient but computationally expensive, plus model errors can really screw you over. Model-free just learns directly from trial and error, which is way simpler and more robust. The catch? You'll need a ton more samples to get anywhere. Here's how I think about it: got limited real-world data like in robotics? Definitely go model-based. Can afford to run millions of simulations and want something that won't break? Model-free all the way. Really depends on whether you're more constrained by samples or compute power.
So basically you pre-train your RL agent on similar tasks first, then fine-tune it for your actual problem. Saves a ridiculous amount of training time since it already knows useful stuff. The trick is finding tasks that share features - like training on one racing game transfers pretty well to another racing environment. Progressive networks work great for this, or you could try domain randomization when you're doing the initial training. Honestly, I'd start by figuring out what parts of your problem overlap with simpler versions or existing models you can build on.
Dude, it's crazy how much RL has changed. Better GPUs plus smarter algorithms mean we went from basic grid worlds to agents crushing StarCraft II and Go. Deep Q-Networks started it all by handling high-dimensional problems, then policy gradient methods came along and worked way better at scale. You can tackle ridiculously ambitious projects now that would've been pipe dreams ten years ago. Though honestly, the field moves so fast it's hard to keep up sometimes. Just make sure you've got the compute budget for whatever you're planning - that stuff adds up quick.
Honestly, bias in your training data is probably your biggest headache - if you're training on biased historical healthcare data, you'll just end up discriminating against certain patient groups. Explainability's huge too since doctors and regulators won't trust a black box making treatment calls. Safety's obvious, especially for autonomous systems where mistakes kill people (fun times). Oh, and good luck figuring out who's liable when things go wrong! I'd start by really digging into your training data to spot bias patterns. Also build interpretability in from the start - way harder to retrofit later.
So researchers are getting pretty clever with this - they're breaking big problems into smaller pieces using hierarchical methods, plus meta-learning that helps agents pick up new skills faster. Real-time stuff is where it gets interesting though. Model-free approaches let agents adapt without rebuilding everything, which is huge for dynamic situations. Oh, and the distributed training across multiple agents is honestly kind of insane when you see it work. I'd definitely keep an eye on multi-agent systems and transfer learning research. Those areas directly tackle the messy, changing environments you'll probably deal with. Continual learning is another solid area worth following.
-
Every time I ask for something out-of-the-box from them and they never fail in delivering that. No words for their excellence!
-
Loved the templates on SlideTeam, I believe I have found the go to place for my presentation needs!