

Machine Learning Operations Powerpoint Presentation Slides





Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


Check out our professionally designed Machine Learning Operations PowerPoint Presentation. This presentation on Machine Learning Operations MLOps offers an introduction to MLOps and presents a comprehensive workflow outlining the architecture of a machine learning pipeline. This workflow spans multiple stages data preparation, model training, model analysis, and model serving. Each of these steps is vital for the overall success of the MLOps process. Additionally, in the MLOps System template, we delve into the essential elements that constitute MLOps. This includes data preparation, where data is refined, transformed, and readied for model training. Furthermore, the AutoML slides explain the four fundamental pillars of MLOps production model deployment, production model monitoring, production model lifecycle management, and production model governance. These pillars ensure that ML models are deployed, scalable, reliable, and governed to uphold compliance and ethical considerations. Lastly, the DevOps section provides a practical framework for managing ML models in production environments. This framework covers various stages, components, and roles while adhering to DevOps principles. A solid understanding of MLOps and its pillars is critical for successfully operationalizing and maintaining machine learning models. Get access to this 100 percent editable template now.
People who downloaded this PowerPoint presentation also viewed the following :
Content of this Powerpoint Presentation
Slide 1: This slide introduces Machine Learning Operations. State your company name and begin.
Slide 2: This is an Agenda slide. State your agendas here.
Slide 3: This slide shows Table of Content for the presentation.
Slide 4: This slide shows title for topics that are to be covered next in the template.
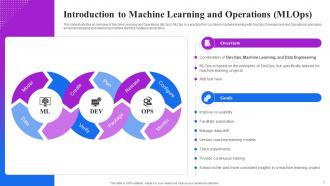
Slide 5: This slide illustrates an overview of Machine Learning and Operations (MLOps). MLOps is a practice that combines machine learning with DevOps.
Slide 6: This slide talks about Development and Operations and introduce the concept of Development and Operations (DevOps) and its importance.
Slide 7: This slide highlights the increasing demand for MLOps due to the proliferation of machine learning and artificial intelligence in various industries.
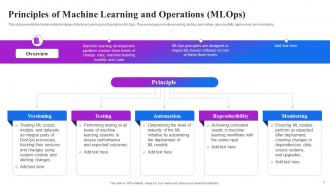
Slide 8: This slide presents the fundamental principles of Machine Learning and Operations (MLOps). These principles include versioning, testing, automation etc.
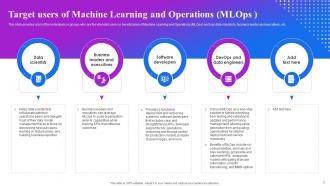
Slide 9: This slide provides a list of the individuals or groups who are the intended users or beneficiaries of Machine Learning and Operations (MLOps.
Slide 10: This slide shows title for topics that are to be covered next in the template.
Slide 11: This slide displays the significant advantages that businesses can achieve by implementing MLOps practices.
Slide 12: This slide provides Benefits of Machine Learning and Operations (MLOps). The purpose of this slide is to presents the primary advantages of implementing Machine Learning.
Slide 13: This slide shows title for topics that are to be covered next in the template.
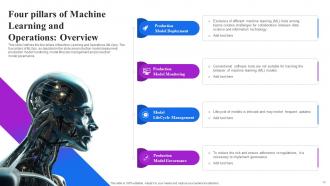
Slide 14: This slide outlines the four pillars of Machine Learning and Operations (MLOps).
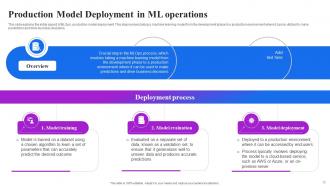
Slide 15: This slide explains the initial aspect of MLOps, production model deployment. This involves taking a machine learning model from the development phase to a production.
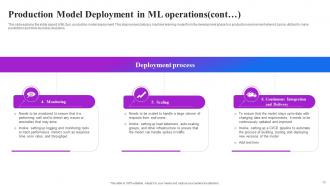
Slide 16: This slide also explains the initial aspect of MLOps, production model deployment. This involves taking a machine learning model from the development phase to a production.
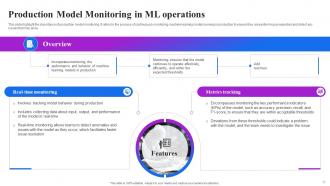
Slide 17: This slide highlight the importance of production model monitoring. It refers to the process of continuously monitoring machine learning models.
Slide 18: This slide displays the importance of production model monitoring. It refers to the process of continuously monitoring machine learning models.
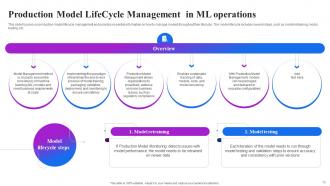
Slide 19: This slide focuses on production model lifecycle management and provides essential information on how to manage models throughout their lifecycle.
Slide 20: This slide also focuses on production model lifecycle management and provides essential information on how to manage models throughout their lifecycle.
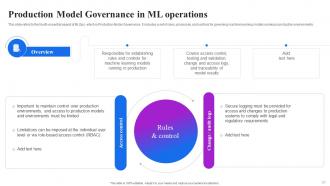
Slide 21: This slide refers to the fourth essential aspect of MLOps, which is Production Model Governance. It includes a set of rules, processes etc.
Slide 22: This slide also refers to the fourth essential aspect of MLOps, which is Production Model Governance. It includes a set of rules, processes etc.
Slide 23: This slide shows title for topics that are to be covered next in the template.
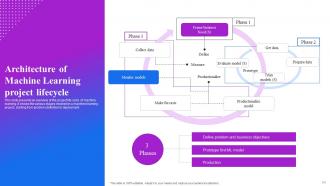
Slide 24: This slide presents an overview of the project life cycle of machine learning. It shows the various stages involved in a machine learning project.
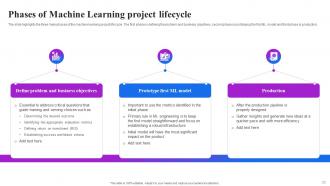
Slide 25: The slide highlights the three main phases of the machine learning project life cycle.
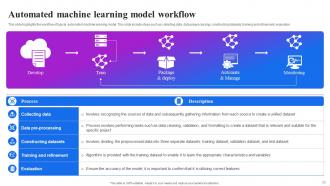
Slide 26: This slide displays the workflow of typical automated machine learning model.
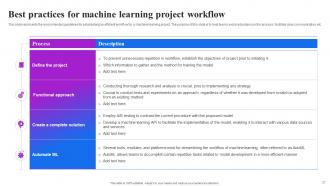
Slide 27: This slide represents the recommended guidelines for establishing an efficient workflow for a machine learning project.
Slide 28: This slide shows title for topics that are to be covered next in the template.
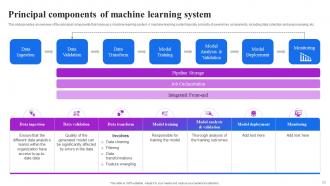
Slide 29: This slide provides an overview of the principal components that make up a machine learning system.
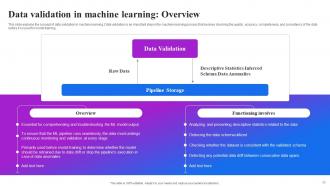
Slide 30: This slide explains the concept of data validation in machine learning. Data validation is an important step in the machine learning process.
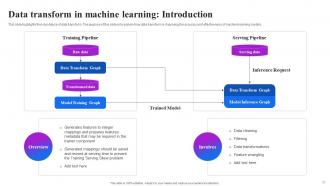
Slide 31: This slide highlights the importance of data transform. The purpose of this slide is to explain how data transform is improving machine learning models.
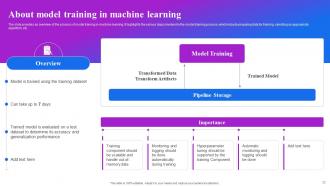
Slide 32: The slide provides an overview of the process of model training in machine learning. It highlights the various steps involved in the model training process etc.
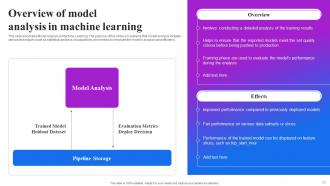
Slide 33: This slide elaborates Model Analysis in Machine Learning and explains that model analysis includes various techniques.
Slide 34: This slide shows title for topics that are to be covered next in the template.
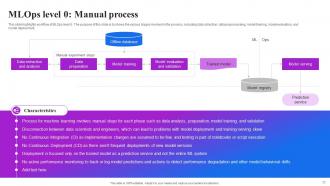
Slide 35: This slide highlights workflow of MLOps level 0. The purpose of this slide is to shows the various stages involved in the process etc.
Slide 36: This slide describe the challenges faced in manual process of MLOps and discusses the difficulties and issues associated with manually implementing MLOps.
Slide 37: This slide shows title for topics that are to be covered next in the template.
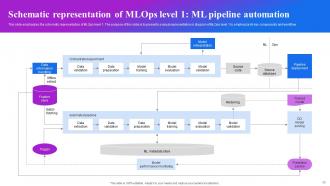
Slide 38: This slide emphasizes the schematic representation of MLOps level 1 and presents a visual representation or diagram of MLOps level 1.
Slide 39: This slide focuses on the characteristics of MLOps level 1, which is all about ML pipeline automation.
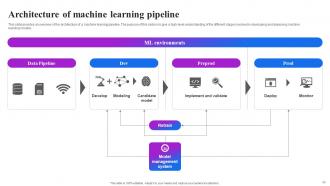
Slide 40: This slide provides an overview of the architecture of a machine learning pipeline.
Slide 41: This slide shows title for topics that are to be covered next in the template.
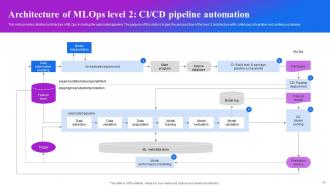
Slide 42: This slide provides detailed architecture of MLOps including the automated pipeline.
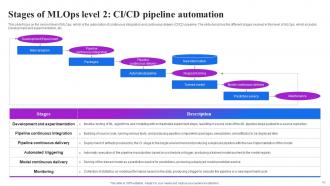
Slide 43: This slide focuses on the second level of MLOps, which is the automation of continuous integration and continuous delivery (CI/CD) pipeline.
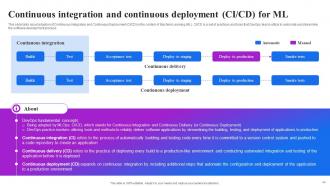
Slide 44: This slide talks about adoption of Continuous Integration and Continuous Deployment (CI/CD) in the context of Machine Learning (ML).
Slide 45: This slide shows title for topics that are to be covered next in the template.
Slide 46: This slide offers a summary of commonly used tools and technologies in the field of MLOps.
Slide 47: This slide provides more information about MLflow, which is a tool used for tracking experiments and managing model metadata in the field of machine learning.
Slide 48: This slide describes Kedro as a tool for MLOps that focuses on orchestration and workflow pipelines.
Slide 49: This slide gives an overview of the data and pipeline versioning tool called Data Version Control (DVC).
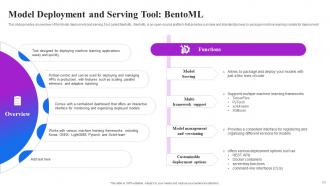
Slide 50: This slide provides an overview of the Model deployment and serving Tool called BentoML.
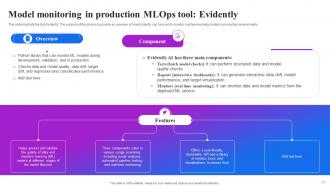
Slide 51: This slide illustrate the tool Evidently. The purpose of the slide is to provide an overview of how Evidently can be used to monitor machine learning models.
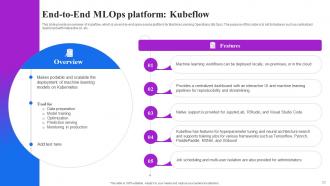
Slide 52: This slide provides an overview of Kubeflow, which is an end-to-end open-source platform for Machine Learning Operations (MLOps).
Slide 53: This slide shows title for topics that are to be covered next in the template.
Slide 54: This slide illustrates the comparison between MLOps (Machine Learning Operations) and DevOps (Development Operations) and determine which is best for an organization.
Slide 55: This slide focuses on the comparison and relationship between two practices in software development: DevOps and MLOps.
Slide 56: This slide aims to highlight benefits and downsides of MLOps and DevOps and identify and examine both the advantages and disadvantages of two related practices.
Slide 57: This slide bring forward the Key differences between roles of team members in DevOps and MLOps.
Slide 58: This slide shows title for topics that are to be covered next in the template.
Slide 59: This slide highlights the differences between Machine Learning and Operations (MLOps) and Artificial Intelligence for IT Operations (AIOps).
Slide 60: This slide elaborate the comparison between machine learning and traditional software development.
Slide 61: This slide provide a clear understanding of the distinctions between these two roles in the context of their work, responsibilities, skill sets, and education.
Slide 62: This slide shows title for topics that are to be covered next in the template.
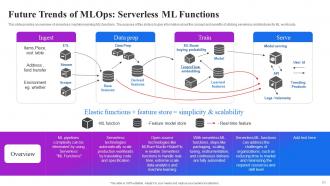
Slide 63: This slide provides an overview of serverless machine learning (ML) functions and gives information about the concept and benefits of utilizing serverless architectures.
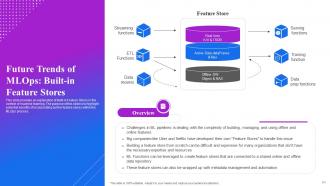
Slide 64: This slide presents an explanation of Built-in Feature Stores in the context of machine learning.
Slide 65: This slide shows title for topics that are to be covered next in the template.
Slide 66: This slide shows RACI matrix for the complete MLOps (Machine Learning Operations) process.
Slide 67: This slide shows title for topics that are to be covered next in the template.
Slide 68: This slide describes the checklist for ongoing MLOps project for an organization.
Slide 69: This slide provides a plan for the first 30, 60, and 90 days of an MLOps project.
Slide 70: This slide illustrates a roadmap for completing an MLOps project in an effective manner.
Slide 71: This slide displays a timeline for the implementation of an MLOps project, which involves several stages that must be completed within specific time frames.
Slide 72: This slide shows title for topics that are to be covered next in the template.
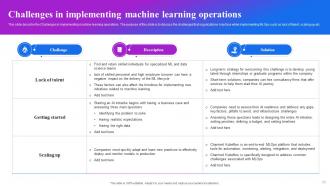
Slide 73: This slide describes the Challenges in implementing machine learning operations and discusses the challenges faced while implementing MLOps.
Slide 74: This slide also describes the Challenges in implementing machine learning operations and discusses the common challenges faced while implementing MLOps.
Slide 75: This slide discusses the common challenges businesses face when implementing MLOps practices and their potential solutions.
Slide 76: This slide shows all the icons included in the presentation.
Slide 77: This slide is titled as Additional Slides for moving forward.
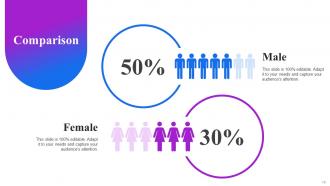
Slide 78: This is a Comparison slide with additional textboxes and related imagery.
Slide 79: This is a Quotes slide to convey message, beliefs etc.
Slide 80: This slide displays Mind Map with related imagery.
Slide 81: This slide shows SWOT analysis describing- Strength, Weakness, Opportunity, and Threat.
Slide 82: This slide contains Puzzle with related icons and text.
Slide 83: This is Our Team slide with names and designation.
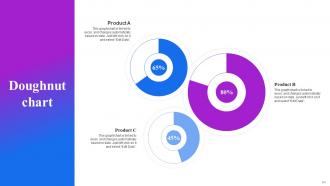
Slide 84: This slide displays Doughnut Graph with three products comparison.
Slide 85: This is a Timeline slide. Show data related to time intervals here.
Slide 86: This is a Thank You slide with address, contact numbers and email address.
Machine Learning Operations Powerpoint Presentation Slides with all 94 slides:
Use our Machine Learning Operations Powerpoint Presentation Slides to effectively help you save your valuable time. They are readymade to fit into any presentation structure.













































FAQs for Machine Learning Operations
Honestly, there are six things you really need to nail down. Data versioning is where everyone screws up first - can't reproduce jack without it. Training pipelines should run the whole show automatically, from prepping data to validating models. CI/CD for models comes next, plus real-time monitoring for when things start drifting. Oh, and some governance layer for compliance stuff. My advice? Get your data and training pipelines rock solid before you dive into all the monitoring bells and whistles. That's where I'd start anyway.
So MLOps is basically DevOps but for machine learning stuff. Regular DevOps just deploys code, right? But with ML you've got all this extra baggage - data versions, training pipelines, tracking when your models start sucking over time. Your CI/CD pipeline becomes a nightmare honestly. You're juggling datasets that keep changing, experiment results, different model versions, retraining schedules... it's a lot. Oh and models can just randomly get worse if the real-world data shifts. My advice? Don't rebuild everything. Just extend whatever DevOps tools you're already using.
Dude, automation is everything in MLOps. It handles the boring repetitive tasks so you don't have to manually deploy every single time. Your whole pipeline gets automated - data validation, training, testing, deployment. Way faster releases and honestly, humans make stupid mistakes that automation just doesn't. When stuff breaks (which happens more than you'd think), automated rollbacks will save your ass. The continuous integration part is pretty sweet too - you push code, tests run by themselves, passes the checks, boom your model's live. Oh and start with just automating your testing first, don't try to do everything at once.
So for your code and configs, just stick with regular Git - that part's easy. But datasets and trained models? Way too chunky for Git. I'd go with DVC since it plays nice with Git but stores the big files in cloud storage separately. MLflow's decent too if you're mainly worried about model versions. Dataset versioning is honestly such a headache, but you'll thank yourself later for doing it right. Track your raw data AND any preprocessing you do. Oh, and don't overcomplicate it at first - start with DVC plus whatever Git setup you've got going.
Track three big buckets: how well your model actually performs (accuracy, precision, recall), whether it's running smoothly (latency, error rates), and if it's moving the needle business-wise (conversions, revenue, engagement). Infrastructure stuff matters too - CPU, memory, deployment health. Nobody wants to get paged at 3am because the model torched production! Data drift is sneaky and will bite you eventually since real-world data shifts constantly. Set up automated alerts so you catch problems before your boss does. The trick is knowing what "normal" looks like for each metric.
So MLOps basically handles data drift by setting up continuous monitoring - you get real-time alerts when your model's accuracy drops or data starts looking weird. The automated retraining is where it gets cool though. When drift hits certain thresholds, it'll retrain your model automatically, validate it, then deploy without you lifting a finger. You also get version control for everything, which saves your butt if you need to rollback. Oh, and definitely start with just basic performance monitoring first - don't try to automate everything at once.
Get ops involved from the start - don't wait until deployment. Have cross-team standups and share everything: Git repos, CI/CD, monitoring dashboards. Yeah, you'll need decent docs (ugh, but it saves your butt later). Create clear handoff rules so nobody's confused when stuff breaks at 2am. Gradual rollouts together are huge for catching problems early. Honestly, the shared ownership thing makes all the difference. Tools matter, but getting everyone on the same page from day one? That's what actually works.
Dude, cloud platforms are lifesavers for MLOps stuff. They handle all the annoying infrastructure work - model training, deployment, monitoring, scaling - so you don't have to mess with it yourself. AWS SageMaker, Azure ML, Google Cloud AI are your main options. Honestly, SageMaker's interface is pretty slick once you get used to it. You'll get automatic scaling, version control, A/B testing, monitoring dashboards without building anything from scratch. Just grab a free tier account and play around - way better than trying to set up your own Kubernetes nightmare. Focus on your actual models instead of DevOps headaches.
Oh man, ML security is no joke. Encrypt your training data first - that's non-negotiable. Authentication for model registries and APIs comes next. Docker containers need hardening too since that's probably how you're deploying. Watch out for data poisoning attacks - hackers love corrupting training sets or just straight-up stealing models. Honestly, the worst part is when a compromised model starts giving users garbage predictions. Log everything, monitor for weird behavior, and scan those dependencies regularly. I learned this the hard way when our image classifier started flagging cats as dogs after a breach.
Honestly, CI/CD is a total game-changer for ML stuff. It handles all the annoying testing and deployment work automatically, so you're not constantly babysitting pipelines or fixing dumb mistakes. Your models actually perform consistently too, which is... rare lol. When things inevitably break in production, rolling back doesn't make you want to quit your job. The best part? Automated validation catches data drift and performance issues before users start complaining. I'd say start with just automating your training pipeline tests first. Don't try to do everything at once - your future self will thank you.
Oh man, the scaling nightmare is real. Data governance becomes a total mess, and don't even get me started on model versioning. Your data science folks want their shiny tools while ops is screaming for standards - been there, it's exhausting. Monitoring tons of models in production? Good luck with that. Everyone just does whatever they want instead of following actual processes. Honestly, nail down experiment tracking and a solid model registry before you go crazy with scaling. And yeah, get your team workflows sorted early or you'll hate your life later.
Honestly, MLOps is a lifesaver for compliance stuff. It automatically tracks all the things regulators want to see - model versions, training data, how decisions get made, performance over time. You'll get audit trails without thinking about it. The bias monitoring dashboards are pretty sweet too. Start with model versioning and experiment tracking first - trust me on this one. When auditors show up (and they will), you'll already have your interpretability reports ready to go. Way better than scrambling to document everything after the fact. Plus it generates all that governance paperwork automatically, which honestly saves so much time.
So there's a ton of options out there - MLflow's solid for tracking experiments, Kubeflow if you're doing Kubernetes stuff. Cloud-wise you've got SageMaker, Vertex AI, Azure ML. Weights & Biases is getting pretty popular for monitoring too. Oh and DVC for data versioning, Feast for feature stores... honestly it changes so fast I can barely keep up lol. My take? Just pick one complete platform first instead of mixing a bunch of tools. Like if you're already using AWS, go with SageMaker. Way easier than piecing everything together yourself. You can get fancy with specialized tools later once you actually know what you need.
Honestly, reproducibility comes down to three things you gotta nail. First, version your data with DVC and obviously use Git for code. Docker containers are clutch for locking down your environment - I can't stress this enough. Random seeds will bite you if you're not careful, so set them for everything (training, data splits, whatever). Track your hyperparameters with MLflow or Weights & Biases. The whole point is someone else should be able to grab your experiment and get identical results. Oh, and start with containerizing your training pipeline - makes everything else way easier.
Honestly, AutoML is getting crazy good - your non-tech people can actually build decent models now. Edge deployment is everywhere since companies want that local speed and privacy thing. MLOps platforms keep merging, which is kinda annoying for picking vendors tbh. Real-time monitoring isn't optional anymore, it's just expected. Oh, and sustainable ML is trending hard - everyone's obsessing over energy costs. I'd start by figuring out where you actually are maturity-wise, then see what fits your needs. Don't chase every shiny trend though.
-
Thanks to SlideTeam, we have an ideal template to present all the info we need to cover. Their slides give our numbers and projections a more clear and enchanting look.
-
“Thanks to SlideTeam. Now I can make smart presentations in a fraction of time without any hassle.”