


Back propagation neural network in ai powerpoint presentation slide templates complete deck





Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


Our Back Propagation Neural Network In AI Powerpoint Presentation Slide Templates Complete Deck are topically designed to provide an attractive backdrop to any subject. Use them to look like a presentation pro.
People who downloaded this PowerPoint presentation also viewed the following :
Content of this Powerpoint Presentation
Slide 1: This slide introduces Back Propagation Neural Network In AI. State your company name and begin.
Slide 2: This slide highlights the Table of Contents, i.e., Introduction to AI, Machine Learning, Deep Learning, along with the Difference between AI, ML, and DL.
Slide 3: This slide further supports the Table of Contents, i.e., Supervised Machine Learning, Unsupervised Machine Learning.
Slide 4: This slide further supports the Table of Contents, i.e., Reinforcement Learning, Back Propagation Neural Network in AI, and Expert System in Artificial Intelligence.
Slide 5: This slide gives you a brief overview of Artificial Intelligence and the most pressing questions related to the same: AI?, Introduction to AI Levels?, Types of Artificial Intelligence? Where is AI used?, Difference between AI, DL, & ML?, AI Usecases?, Why is AI booming now?, and AI trend in 2020?
Slide 6: This slide acquaints you with the widely renowned definition of Artificial intelligence (AI), Deep Learning, and Machine Learning to get you started.
Slide 7: This slide informs you about the various AI levels, such as Artificial Narrow Intelligence, Artificial General Intelligence, and Artificial Super Intelligence.
Slide 8: This particular slide displays the wide range of Deep Learning, Machine Learning, and Artificial Intelligence.
Slide 9: The following slides provide you detailed information about Artificial Intelligence and the various elements associated with it.
Slide 10: This slide titled - Machine Learning, provides you with deep insights into the concept of AI and its types.
Slide 11: The following slide showcases the information on Deep Learning and its key functions known as artificial neural networks.
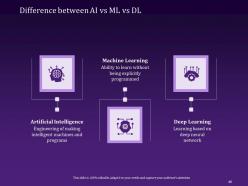
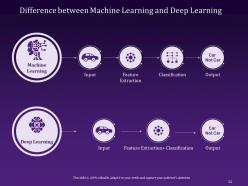
Slide 12: This slide is designed to clearly demarcate the difference between the three concepts in a well-structured 'AI VS Machine Learning VS Deep Learning' format.
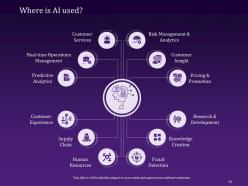
Slide 13: This slide answers the crucial question of the uses of AI with Customer Experience, Supply Chain, Human Resources, Fraud detection, Knowledge creation, Research & Development, Risk Management & Analytics, Predictive Analytics, Real-time operations management, customer services, customer insights, Pricing & promotion.
Slide 14: The following slide displays the AI Usecase in HealthCare: Research, Training, Keeping well, Early detection, Diagnosis, Decision Making, Treatment, and End of Life Care.
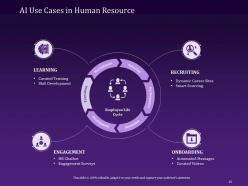
Slide 15: This slide focuses on the uses of Artificial Intelligence in the Human Resource department that includes learning, Selection, Recruitment, engagement, and onboarding.
Slide 16: This slide covers how banking benefits from AI for Fraud Detection using a Neural network engine and a Scoring engine.
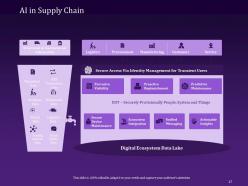
Slide 17: The following slide illustrates the role of AI in the Supply Chain that includes logistics, procurement, manufacturing, customers, and service.
Slide 18: This slide introduces you to all the AI Chatbots in Healthcare, such as search engines, social platforms, smartphones, health bots, artificial intelligence, messenger apps, and the app ecosystem.
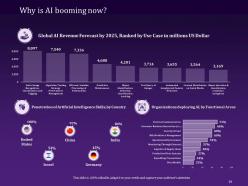
Slide 19: This slide discusses the reason for Why AI is booming now, with proper logistics and statistics.
Slide 20: This slide goes on to exhibit the top 10 AI trends in 2020. This includes AI in Retail, Robotic process automation, Aerospace and flight operations controlled by AI, Advanced cybersecurity, AI mediated media, and entertainment, data modeling, AI in healthcare, B2B, AI-powered chatbots, and automated business processes.
Slide 21: 2This slide mentions the burning questions related to Machine Learning like What is ML, 7 steps of machine learning, machine learning vs. traditional programming, How does machine learning work, machine learning algorithms, machine learning use cases, how to choose ML algorithm, why to use decision tree algorithm learning, challenges, and limitations of machine learning, applications of machine learning, and Why is machine learning important?
Slide 22: The following slide is designed to display the working mechanism of Machine Learning and its input and output data.
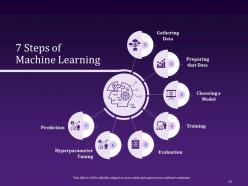
Slide 23: This next slide defines the key seven Steps of Machine Learning that are gathering data, choosing a model, preparing the data, evaluation, prediction, hyperparameter tuning, training.
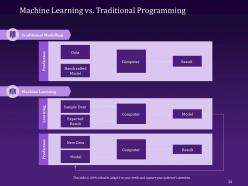
Slide 24: This slide draws a comparison between machine learning and traditional programming.
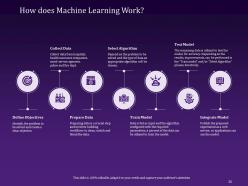
Slide 25: The following slide describes how Machine Learning Work includes - defining Objectives, preparing data, train Model, integrate Model, Collecting data, Selecting algorithm, and test Model.
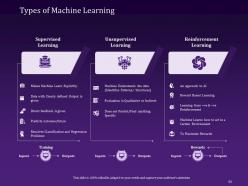
Slide 26: This slide visually represents the Machine Learning Algorithms, including supervised, unsupervised, and reinforcement, in an organized format.
Slide 27: The following slide highlights the Machine Learning Use Cases by emphasizing important elements like energy feedback & utilities, financial services, travel & hospitality, manufacturing, retail, healthcare & life sciences, etc.
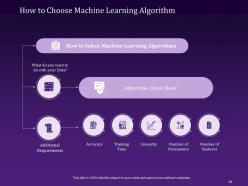
Slide 28: This slide educates you on Choosing a Machine Learning Algorithm, algorithm cheat sheet, and additional requirements like accuracy, training time, linearity, parameters, and the number of features.
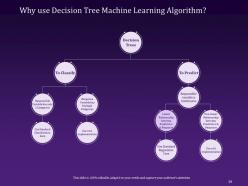
Slide 29: This slide mentions the reasons for using Decision Tree Machine Learning Algorithm to classify or predict, and further their uses.
Slide 30: This slide highlights to Challenges and Limitations of Machine learning.
Slide 31: This slide showcases the essential components in the Application of Machine Learning like Automatic Language Translation, Medical Diagnosis, Stock market trading, online fraud detection, Virtual Personal assistants, email spam and malware filtering, self-driving cars. Product Recommendations, Traffic Prediction, Speech Recognition, image recognition.
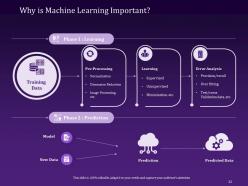
Slide 32: This slide aims to explain the importance of Machine Learning along with the key phases of learning and prediction.
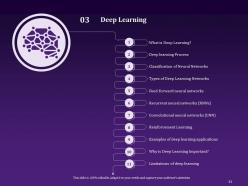
Slide 33: This slide is curated to address all the critical questions with regards to the concept of Deep Learning like what is deep learning, deep learning process, classification of neural networks, types of deep learning networks, feed-forward neural networks, recurrent neural networks, convolutional neural networks, reinforcement learning, examples of deep learning applications, why is deep learning important, and limitations of deep learning.
Slide 34: This next slide further provides a brief understanding of Deep Learning; its input, feature extraction & classification, and output.
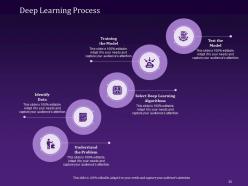
Slide 35: This slide gives you a glimpse of the complex Deep Learning Process which includes understanding the problem, identifying data, selecting deep learning algorithms, training the model, and testing the model.
Slide 36: The following slide gives you the Classification of Neural Networks that consists of Input Layer, Hidden Layer, and Output Layer.
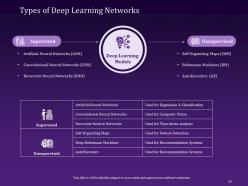
Slide 37: This slide provides information on the various types of deep learning networks: Artificial, Convolutional, Recurrent, Self Organizing Maps, and Boltzmann Machines Neural Networks.
Slide 38: This slide elaborates on the Feed-forward Neural Networks and their input layer, hidden layer, and output layer.
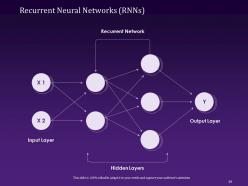
Slide 39: This slide elucidates the Recurrent Neural Networks thoroughly.
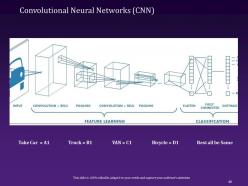
Slide 40: This slide gives a detailed explanation of the Convolutional Neural Networks.
Slide 41: This slide explains how Reinforcement Learning goes on to maximize the rewards.
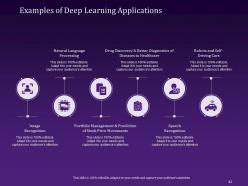
Slide 42: This slide provides you with a wide range of Examples of Deep Learning Applications like image recognition, natural language processing, speech recognition, portfolio management & prediction of stock price movements, drug discovery & better diagnostics of diseases in healthcare, robots, and self-driving cars.
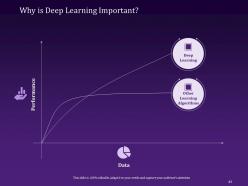
Slide 43: This slide shows Why Deep Learning is Important.
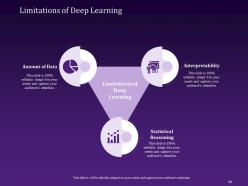
Slide 44: This slide presents the Limitations of deep learning: Interpretability, Statistical Reasoning, and Amount of Data.
Slide 45: The following slide demonstrates the Difference between AI, ML, and DL and the burning questions related to them like What is aI, What is ML, What is Deep learning, Machine learning process, deep learning process, the difference between machine learning and deep learning, and which is better to start - AI, ML, or deep learning?
Slide 46: This slide visually represents the Difference between AI, ML, and DL in an attractive yet informative manner.
Slide 47: This slide provides you detailed information about Artificial Intelligence.
Slide 48: The current slide gives you an introduction to Machine Learning and how it learns, predicts, and improves the ordinary system.
Slide 49: This slide will take you through the concept of Deep Learning in detail.
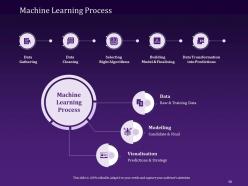
Slide 50: This slide explains the Machine Learning Process that consists of steps like Data Gathering, Data Cleaning, Selecting Right Algorithms, Building Model & Finalising, and Data Transformation into predictions.
Slide 51: This slide takes you through the Deep Learning Process that includes understanding the problem, identifying data, selecting deep learning algorithms, training the model, and testing the model.
Slide 52: The purpose of this slide is to highlight the difference between Machine Learning and Deep Learning.
Slide 53: This slide explains which one is better to start with - Artificial intelligence(AI), Machine learning(ML), or Deep learning(DL).
Slide 54: This slide titled Supervised Machine Learning focuses on explaining the concept by addressing questions like types of machine learning, what is supervised machine learning, how supervised learning works, types of supervised machine learning algorithms, supervised vs unsupervised learning techniques, advantages of supervised learning, and disadvantages of supervised learning.
Slide 55: The following slide provides you with various types of Machine Learning like supervised learning, unsupervised learning, and reinforcement learning.
Slide 56: This slide defines What Supervised Machine Learning is.
Slide 57: This slide mentions the mechanism of How Supervised Machine Learning works and all the steps it entails, like classification and regression.
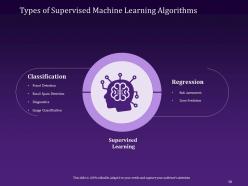
Slide 58: This slide brings various Types of Supervised Machine Learning Algorithms to the fore, like classification that includes fraud detection, email spam detection, diagnostics, and image classification. It also includes risk assessment and score prediction.
Slide 59: This slide calls attention to Supervised (classification, regression) vs. Unsupervised Machine Learning Techniques (clustering, association).
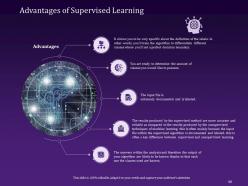
Slide 60: This slide emphasizes the Advantages of Supervised Learning.
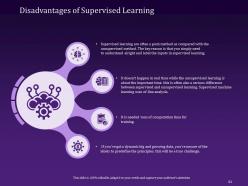
Slide 61: This slide argues about the Disadvantages of Supervised Learning.
Slide 62: This slide addresses the concept of Unsupervised Machine Learning and the questions associated with it, like what is unsupervised machine learning, how unsupervised machine learning works, types of unsupervised learning, and disadvantages of unsupervised learning.
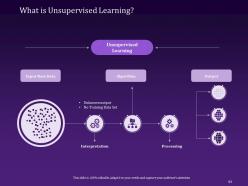
Slide 63: This slide focuses on What Unsupervised Learning is and its input data, algorithms as well as output.
Slide 64: This slide underlines How Unsupervised Machine Learning works and the problems it solves, like clustering and anomaly detection.
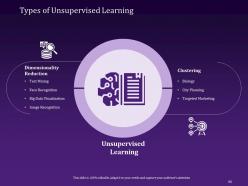
Slide 65: This slide explores the various Types of Unsupervised Learning, such as dimensionality reduction and clustering.
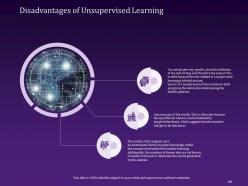
Slide 66: The following slide displays the Disadvantages of Unsupervised Learning.
Slide 67: This slide is titled reinforcement learning. It highlights the questions related to the concept like reinforcement learning, how reinforcement learning works, types of reinforcement learning, advantages, and disadvantages of reinforcement learning.
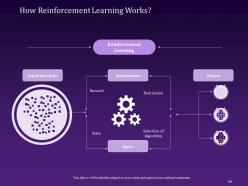
Slide 68: This slide highlights the concept of Reinforcement Learning and its key steps like input, response, feedback, learning, and reinforcement response.
Slide 69: This slide elaborates on the functioning of Reinforcement Learning and the environment and the agent it deals with.
Slide 70: This slide showcases the Types of Reinforcement Learning like Gaming, Finance Sector, Inventory Management, Manufacturing, and Robot Navigation.
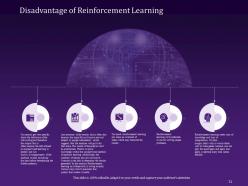
Slide 71: This slide highlights the Disadvantage of Reinforcement Learning.
Slide 72: The purpose of this slide is to talk about Back Propagation Neural Network in AI and the questions related to it, such as backpropagation neural network in AI, what is artificial neural networks, what is backpropagation, why we need backpropagation, what is a feed-forward network, types of backpropagation networks, and best practice backpropagation.
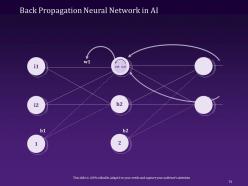
Slide 73: This slide illustrates the role of the Back Propagation Neural Network in AI.
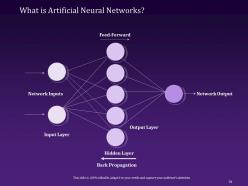
Slide 74: This slide showcases the meaning of Artificial Neural Networks and their key elements like feed-forward, network output, an output layer, hidden layer, input layer, and network inputs.
Slide 75: The purpose of this slide is to explain What is Backpropagation Neural Networking and its input layer, hidden layer, and output layer.
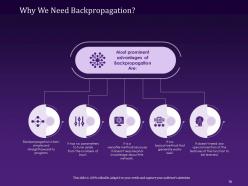
Slide 76: This slide talks about Why We Need Backpropagation.
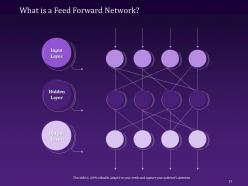
Slide 77: The following slide explains What a Feed-Forward Network is and its input layer, hidden layer, and output layer.
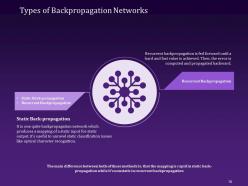
Slide 78: This slide display the two types of Backpropagation Networks that are static back-propagation and recurrent back-propagation.
Slide 79: This current slide highlights the Best Practice Backpropagation.
Slide 80: This slide discusses the key questions related to Expert systems in Artificial Intelligence, which are - what is an expert system, examples of expert system, characteristics of expert system, components of the expert system, conventional system vs expert system, human expert vs expert system, benefits of expert system, limitations of the expert system, and applications of the expert system.
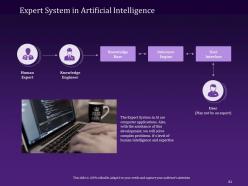
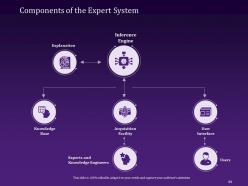
Slide 81: This slide shows the Expert System in Artificial Intelligence and how it utilizes a knowledge base, inference engine, and user interface.
Slide 82: This slide provides you with a wide range of Examples of Expert Systems, including high expertise, right on time reaction, good reliability, flexible, effective mechanism, and capable of handling challenging decisions & problems.
Slide 83: The purpose of this slide is to address the important Characteristics of an Expert System that are high-level performance, domain specificity, good reliability, understanding, adequate response time, and symbolic representations.
Slide 84: The following slide provides the list of essential Components of the Expert System that entails inference engine, acquisition facility, user interface, knowledge base.
Slide 85: This slide gives the difference between Conventional systems and Expert systems.
Slide 86: This slide gives you proper Human Expert vs. Expert System information.
Slide 87: This slide mentions the Benefits of Expert Systems such as Fast Response, Ease to Develop and Modify, Low Accessibility Cost, low Error Rate, and Data Warehousing.
Slide 88: The following slide goes through all the Limitations of the Expert System.
Slide 89: This slide talks about the Applications of Expert Systems such as knowledge domain, finance/commerce, repairing, warehousing optimization, shipping, design domain, medical domain, monitoring system, and process control system.
Slide 90: This slide gives icons regarding Back Propagation Neural Network in AI.
Slide 91: The purpose of this slide is to give an introduction to additional slides.
Slide 92: This slide conveys the company's vision, mission, and goals in an attractive yet informative manner.
Slide 93: This slide is titled Post It Notes for highlighting key information.
Slide 94: This slide conveys the goals of a company or its projects.
Slide 95: This slide exhibits the Bar Chart for comparison of your products.
Slide 96: This slide exhibits the Area Chart for comparison of your products.
Slide 97: The purpose of this slide is to cover the financial aspects of your company.
Slide 98: This is a Thank You slide with contact, address, and email details.
Back propagation neural network in ai powerpoint presentation slide templates complete deck with all 98 slides:
Use our Back Propagation Neural Network In AI Powerpoint Presentation Slide Templates Complete Deck to effectively help you save your valuable time. They are readymade to fit into any presentation structure.
























































FAQs for Back propagation neural network in ai powerpoint presentation slide
So neural networks learn by working backwards from their mistakes. Your network makes a prediction, sees how wrong it was, then traces back through each layer to figure out which connections screwed up the most. Kind of like when you bomb a test and go through each problem to see where you messed up. The network tweaks those weights to do better next time. This happens over and over during training - honestly it's pretty clever. You should try coding it with an XOR problem first, way easier to wrap your head around when you can see the error actually flowing backwards.
So backpropagation works backwards through your network using the chain rule - it figures out how much each weight screwed up the final prediction. Start with your loss at the output, then trace that error back layer by layer. Think of it like following breadcrumbs but in reverse. Each step calculates partial derivatives to see which weights are the biggest troublemakers. Then you multiply those gradients by your learning rate to update the weights. Honestly, the math looks scarier than it is - you're just finding slopes. Pro tip: print out the gradients when you code it up, watching them flow backwards is pretty satisfying.
So basically, the derivative of your activation function controls how gradients flow back through your network during training. You need those derivatives to figure out how much each weight messed up the final prediction - that's literally what backpropagation does. ReLU got super popular because its derivative is dead simple (just 1 or 0). Compare that to sigmoid with its annoying exponential math. If your activation's derivative gets too tiny, you'll hit vanishing gradients and your early layers won't learn anything useful. Honestly, just pick something that keeps gradients flowing smoothly through all your layers.
So learning rate is basically how big steps your model takes when updating weights. Too high? Your model just bounces around like crazy and never settles on anything good. Go too low and training takes forever - plus you might get stuck in some random local minimum. I usually start with 0.001, maybe 0.01 if I'm feeling spicy. Most people do learning rate schedules where it drops over time, which honestly works way better than keeping it fixed. It's super annoying to tune but makes a huge difference. Just gotta experiment until you find that sweet spot.
So backprop gets messy with deep networks - gradients either vanish or explode as they bounce through layers. Training slows to a crawl because you're updating tons of parameters. Memory usage? Forget about it, these things are hungry. Plus they overfit like crazy on training data. Honestly though, most of this stuff is pretty solvable now. Gradient clipping helps with the explosion problem. Xavier or He initialization makes a huge difference from the start. Residual connections are your friend for really deep stuff, and dropout handles overfitting. I'd start there - you'll notice way more stable training pretty quickly.
Oh wait, backprop isn't really an optimization thing - it just calculates gradients. You're mixing it up with gradient descent! So backprop works backwards through your network using chain rule to figure out gradients. Then the actual optimizers like SGD or Adam take those gradients and update your weights. Backprop says "go this way" and the optimizer decides how far to step. Without backprop, gradient descent would be totally screwed for deep networks since calculating gradients manually would be a nightmare. You should try coding a simple one yourself - really helps it click.
So backpropagation doesn't actually fix overfitting - it kinda makes it worse because it gets too good at memorizing your training data. What you need is regularization on top of it. Dropout is probably your best bet (randomly shuts off neurons during training, which sounds weird but works great). L1/L2 regularization penalizes huge weights. Early stopping is clutch too - just halt training when your validation loss starts going up. Oh and always watch that validation loss! If it's way different from training loss, you're definitely overfitting. I'd start with dropout and early stopping first.
Ugh, vanishing gradients are the worst - your early layers basically stop learning because the gradients get tiny by the time they reach back. Then you've got exploding gradients doing the opposite thing, which is equally annoying. Your network also loves getting stuck in crappy local minima instead of finding the actual best solution. ResNet with skip connections is probably your best bet to start with. Adam optimizer helps too, and honestly just using proven architectures beats trying to reinvent the wheel. I wasted so much time building from scratch when I started.
So backprop is basically the same everywhere - you're just calculating gradients and pushing errors backward. CNNs need you to handle the convolution layers in reverse (some weird math there). RNNs get messier since you're dealing with sequences and shared weights over time steps - that's "backpropagation through time." Honestly though? PyTorch does like 90% of this for you now. I'd focus on really nailing the forward pass first. Once you get how data flows forward, the backward stuff clicks way easier. Trust me on that one.
Okay so think of the loss function as your model's report card - it shows exactly how badly you're screwing up compared to the right answers. When you run backprop, you're literally working backwards from that loss score to figure out which weights need tweaking. It's kinda like when your GPS realizes you took a wrong turn and has to recalculate. Pick the wrong loss function though? Your model will optimize for completely the wrong thing. Cross-entropy works great for classification, MSE for regression - but honestly, this choice makes or breaks everything your network learns.
So batch size is kinda tricky - bigger batches give you smoother gradients and use your GPU better, but they eat tons of memory and can get trapped in crappy spots. Smaller ones are messier but that noise actually helps! They update way more often too. I usually just start with 64 or 128 and see what happens. Honestly, between 32-256 is the sweet spot for most stuff. Just watch your loss curves - if they're all over the place, go bigger. If you're running out of VRAM, go smaller. There's definitely some trial and error involved.
Dude, backprop has come SO far since the basic version. Adam optimizer is probably the biggest win - it handles learning rates automatically so you don't have to mess around with tuning. Batch normalization speeds things up by normalizing between layers. Dropout prevents overfitting pretty well too. Momentum-based methods help you break out of those annoying local minima. RMSprop and AdaGrad are solid choices too, honestly. Learning rate scheduling is newer but works great. Oh and gradient clipping - super helpful when gradients explode. If you're still stuck with vanilla SGD, switch to Adam first. It's basically cheating lol.
Yeah totally! Backprop works great for unsupervised stuff. Autoencoders use it all the time - they just compare their output to the original input instead of some external label. VAEs and GANs do this too. The trick is setting up your loss function differently. Instead of measuring against ground truth labels, you're looking at things like reconstruction error. I actually think it's pretty cool how flexible backprop is. You can definitely use it to find patterns in unlabeled data, just gotta design your architecture right.
So basically you freeze most of the pre-trained layers and only let backprop update your new classifier stuff at the end. Those early conv layers already learned edge detection and textures pretty well, so why mess with them? Start super conservative - keep everything frozen except maybe the last couple layers. If you're still not getting good results, then you can unfreeze more layers but use a tiny learning rate so you don't wreck the features. Oh and sometimes people call this "fine-tuning" when you unfreeze more stuff. Honestly saves you so much training time compared to starting from zero.
Honestly, skip backprop when you're hitting non-differentiable functions or dealing with super sparse gradients. RL is a big one - policy gradients and evolutionary stuff work way better there. Sometimes backprop just can't handle certain reward structures, you know? Online learning scenarios are another good case since you need that real-time adaptation. Oh, and tiny datasets - genetic algorithms might actually beat gradient descent there. If you're constantly fighting vanishing gradients, maybe it's time to try something completely different instead of banging your head against the wall.
-
Design layout is very impressive.
-
Enough space for editing and adding your own content.
-
Presentation Design is very nice, good work with the content as well.
-
Great product with highly impressive and engaging designs.