


Incident Escalation Management Workflow Chart




Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


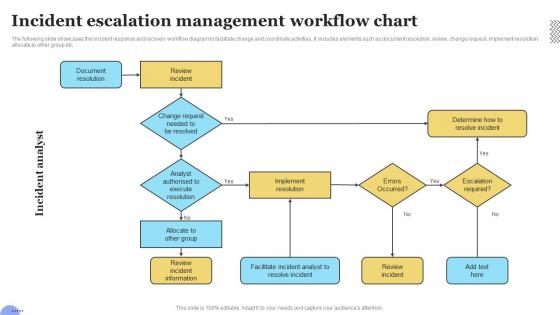
The following slide showcases the incident response and recovery workflow diagram to facilitate change and coordinate activities. It includes elements such as document resolution, review, change request, implement resolution, allocate to other group etc.
People who downloaded this PowerPoint presentation also viewed the following :
Incident Escalation Management Workflow Chart with all 6 slides:
Use our Incident Escalation Management Workflow Chart to effectively help you save your valuable time. They are readymade to fit into any presentation structure.



FAQs for Incident Escalation
So first thing - log it and figure out how bad it is, then get it to whoever can actually fix it. Root cause investigation comes next, obviously. Fix it, test that you didn't break anything else, then document everything before closing. Communication is huge though - people freak out when they don't know what's happening. Honestly, the priority/impact stuff is probably the most important part since it decides your whole timeline and who jumps in. Oh, and use your ticketing system for everything so you can catch patterns later.
So basically you want to look at two things - how badly it's screwing with business operations and how fast you need to fix it. Most places do something like P1 (everything's on fire), P2 (major stuff broken), P3 (annoying but not critical), and P4 (honestly who cares right now). Group them by what type of problem too - security stuff, performance being terrible, complete outages, whatever. The whole point is helping your team know what to jump on first. Don't overcomplicate it though. Start with maybe 3 severity levels and add more if you actually need them later.
Honestly, this stuff can make or break you when everything's on fire. Get your communication channels sorted NOW - not when you're scrambling during an outage. Your incident commander needs to keep everyone looped in constantly, otherwise you'll have teams duplicating work or missing critical steps entirely. Customers hate being left in the dark too. The collaboration part is huge because your experts need to actually work together instead of... well, chaos basically. I learned this the hard way - you really don't want to be figuring out who calls who while your site's down. Set up those escalation paths ahead of time.
Dude, get yourself a decent incident tracking tool first - that's honestly where I'd start. Those automated monitoring systems will catch problems before they turn into disasters. PagerDuty or ServiceNow are solid choices that keep everything organized instead of the usual email chaos. The cool part? AI can actually help figure out what went wrong by looking at similar issues you've had before. Once your tools start talking to each other automatically, that's when things get really smooth. I mean, we used to just wing it with spreadsheets - what were we thinking? Your team will adapt quickly once they see how much easier it makes everything.
So I'd focus on four main ones. MTTR shows how fast you're actually fixing stuff, and MTTD tells you how quickly you catch problems. Track incident volume and recurring incidents too - honestly, dealing with the same issue over and over is the worst. Customer impact duration matters a lot, plus whether your team actually completes those post-incident reviews (we all know how those get skipped sometimes). Don't try to measure everything at once though. Pick 2-3 that match your biggest headaches right now, then add more later.
Start with business impact when you're prioritizing - that's your north star. Set clear SLAs for each level so everyone knows what to expect. Honestly, communication saves your butt more than anything else. Update stakeholders every 30 minutes during big incidents or they'll start freaking out and calling your boss. Get those workarounds documented fast so the business can keep running while you dig into the real fix. Having an incident commander helps too - stops people from tripping over each other. Oh, and write decent runbooks when things are quiet. Your future stressed-out self will thank you. Good monitoring catches stuff before customers start complaining, which is obviously way better.
Honestly? Getting leadership on board is the hardest part. Different teams guard their processes like precious secrets and nobody wants to budge - total nightmare. Money's always an issue too since you need decent tools and training upfront. Most places I've seen completely botch the roles part, so when shit hits the fan everyone's just running around confused. Oh and the silos thing is real - marketing does their thing, engineering does theirs, never the two shall meet. My advice? Pick one small team first. Prove it works, then slowly take over the world.
Do this within 24-48 hours while memories are sharp. Map out the timeline and dig into what broke vs what actually worked. Here's the thing - don't let it become a blame fest or people will clam up next time. Keep asking "why" until you hit the real root cause, not just surface stuff. Someone needs to own each action item with real deadlines. Oh, and share what you learned with other teams too. The biggest mistake? Writing up all these great fixes and then... nothing happens. Those meetings cost real money if you're not gonna act on them.
Honestly, the biggest thing is making sure people don't get thrown under the bus for reporting stuff. I've worked places where managers got all defensive about incidents - reporting just stopped completely. Treat every report like a chance to learn something, not hunt for someone to blame. Make the actual reporting dead simple too - mobile apps or whatever removes the hassle. Leadership has to walk the walk here, talking about their own screw-ups openly. And here's what really matters: actually tell people what you did with their feedback. Close that loop. Nothing kills participation faster than reports disappearing into some void.
Dude, you absolutely need one - it's like having a game plan when shit hits the fan. Without it, your team's just scrambling around trying to figure out who calls who and what comes next. I've watched perfectly smart people waste like 2 hours just on basic stuff during outages because nobody knew the process. Make sure you've got clear escalation steps, communication templates, and who does what. Oh and actually run drills with your team - can't tell you how many companies write these things then never touch them again. It'll save you from the blame game later and keeps compliance happy too.
So basically, incident management becomes your central hub that connects to everything else. When stuff breaks, it automatically kicks off change management for fixes and updates your CMDB. Problem management gets fed the data to hunt down root causes too. Your service desk handles all the routing - honestly, this part can get messy if you don't set it up right initially. The magic happens when your tools actually talk to each other without manual handoffs. I'd start by sketching out how incidents currently ripple through your other processes, then automate those connections. Once the workflows click, it runs pretty smooth.
Get your team ITIL certified first - that's non-negotiable. Everyone should know your runbooks and escalation paths cold. I swear, most incidents drag on just because people don't know who the hell to contact! Run monthly fire drills with realistic scenarios. Set them up with proper monitoring tools and knowledge bases too. Communication training helps since everyone panics under pressure (myself included sometimes). Start by figuring out where your team's weakest, then schedule quarterly practice sessions. Post-incident reviews are clutch for learning what went wrong.
Dude, automation totally changed how we handle incidents at work. It catches issues way faster than we ever could manually. You can set alerts to ping the right people instantly when stuff breaks, plus it auto-creates tickets with all the details already filled in. Status updates get sent out automatically too - no more forgetting to tell everyone what's happening (been there, done that). Your team stops wasting time on boring repetitive tasks. Start with whatever manual process annoys you most and automate that first. Trust me, you'll wonder why you didn't do it sooner.
Dude, pick ONE incident commander immediately - usually whoever's team got hit hardest or knows the systems best. Create a Slack war room but don't invite half the company (seriously, I've watched that chaos unfold). Pull in key people from each affected team, then let the IC actually run things. They should give regular updates and clearly assign who's doing what. Document everything so there's no confusion about ownership later. Oh and definitely do a post-mortem with everyone afterward - you'll want those lessons learned. Trust me, multiple people trying to be in charge just makes everything take twice as long.
Look, how you handle incidents basically makes or breaks customer trust. Quick response plus transparent communication? Customers will actually stick with you even after things go sideways. Respond slowly or keep them in the dark though, and you're screwed - especially since everyone vents on Twitter now. One badly handled outage can torch your reputation for months. You need solid escalation processes and a decent status page. Train your team on talking to customers (not just fixing things), and definitely circle back after you resolve stuff. Shows you actually give a damn about their experience, you know?
-
It's always a delight to see new templates from you! I am extremely pleased with the fact that they are easy to modify and fit any presentation layout in seconds!
-
Their products can save your time, effort and money. What else you need. All in one package for presentation needs!