

Data flow architecture presentation design





Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


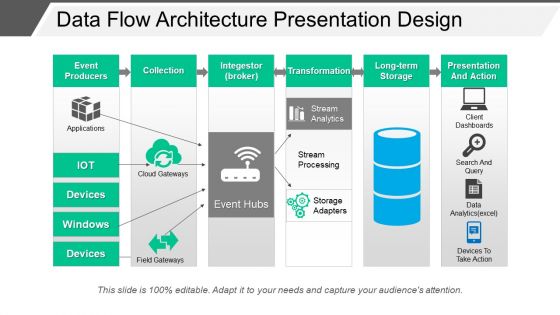
Get over any existing impasse with our data flow architecture presentation design PowerPoint deck. This is a six-stage process which comprises of the following important components crucial to any data system: big data, data architecture, data management. This PowerPoint can be used smartly to highlight the data flow architecture of any data system within a business. The basic building blocks can be conveyed easily as this has been taken care of and has been carefully designed keeping in mind a varied and professional audience in business meetings. Use this PowerPoint layout to pitch your ideas convincingly, satisfy your current customers and explore new buyers. Components like event producers, collection, investor, transformation, long-term storage, and presentation & action can be explained within just one slide making it less complex and less time-consuming. You can now captivate your audience with our data flow architecture presentation design PPT deck at the simple click of a button. Simply download in a snap, add your data and present it to your audience. Get over any existing impasse with our Data Flow Architecture Presentation Design. Clear the decks for further action.
People who downloaded this PowerPoint presentation also viewed the following :
Data flow architecture presentation design with all 5 slides:
Create a glittering effect with our Data Flow Architecture Presentation Design. Eyes will glisten in delight.




FAQs for Data flow
So you're basically dealing with three main pieces: data sources, processing nodes, and data stores. Picture them as producers, transformers, and consumers. Then you've got connectors moving stuff between nodes, plus control mechanisms for orchestration and error handling. Honestly, it's way cleaner than traditional setups since nothing's tightly coupled. Each node just does its thing independently and kicks off when new data shows up. My advice? Map out your data sources first, figure out what transformations you need. That'll help you see which components to tackle first - saves you from going in circles later.
So instead of dumping data into a database and querying it later, data flow architecture processes everything while it's moving. Like catching fish as they swim by rather than waiting for them to hit your pond. Way more dynamic than dealing with static tables, honestly. Your data gets transformed through pipelines in real-time, so you can react to stuff immediately instead of running those annoying overnight batch jobs. I'd start by figuring out what actually needs real-time processing vs what can wait - that'll save you headaches later.
Dude, the biggest win is scalability - your components aren't stuck together so tightly. When something breaks (and it will), it won't take down your whole system. That alone has saved me hours of debugging nightmares. Performance gets way better too since everything can run in parallel. Oh, and tracking down bugs becomes actually doable because you can trace exactly how data flows through each step. Honestly if you're dealing with streaming data or need to scale out, this pattern is a no-brainer. Your future self will thank you.
So basically you break your data processing into parallel streams instead of doing everything one step at a time. Way faster that way. Each piece can scale up independently - like if one part gets slammed, just add more servers to that section only. Your data keeps flowing instead of getting stuck waiting around. Honestly, debugging becomes so much less painful when things are separated out like this. The whole point is distributing your workload across multiple machines so you can actually handle huge amounts of data. I'd start by finding where you're currently getting bottlenecked and turning those parts into standalone components first. Oh, and make sure they're stateless - trust me on that one.
Oh man, real-time processing is a game changer for data pipelines. It handles streaming data as it comes in rather than waiting around for batch jobs. Think fraud detection or monitoring dashboards - you can't wait hours to know something's broken! Tools like Kafka and Flink are solid choices for building these continuous streams. Honestly, I'd figure out what actually needs real-time versus near-real-time first though. You'll avoid overcomplicating things that way. Most recommendation engines work fine with a slight delay anyway.
So data pipelines are basically your plumbing system - they actually move the data around between sources and destinations. Your architecture is like the blueprint showing where everything should flow. Pipelines are the real workflows doing the heavy lifting with ETL stuff and managing dependencies. Every arrow on your diagram? That becomes a pipeline later. Honestly, I'd start by sketching out your data flow architecture first - makes building the actual pipelines way easier since you'll already know the pathways. Don't overthink it though, just match your pipeline design to whatever patterns you've established.
So for event streaming, most people go with Apache Kafka - it's solid. Workflow stuff? Apache Airflow handles that well. Apache Spark's your go-to for big data streams. Honestly though, I'd probably just use cloud options like AWS Kinesis or Google Dataflow first since dealing with infrastructure is such a pain. Real-time processing needs something like Apache Storm or Flink. Oh, and NiFi's decent for routing data around if you're doing batch work. But seriously, figure out what your actual data flow looks like before picking tools. Don't just grab whatever's hot right now.
So basically, data flow architecture treats everything like streams flowing between nodes. Super handy for integration because you don't have to stress about different formats or systems - it's like having universal adapters for all your sources. Each one just talks the same "flow language." You set up transformations at each stage, which handles databases, APIs, real-time feeds, whatever. Adding new sources becomes way more modular instead of rebuilding everything from scratch (which honestly sucks). I'd start by mapping your current sources first, then figure out what transformation patterns you'll actually need.
Don't wait until the end to check your data quality - build those checks right into each step. At ingestion, validate schemas, formats, and completeness. Between transformations, monitor for drift and catch anomalies early. Trust me, I've watched bad data travel through entire pipelines before anyone realized what happened (such a nightmare). Set up automated alerts when quality drops below thresholds. You'll also want clear lineage tracking so you can trace problems back to where they started. Oh, and establish contracts with your upstream systems - that way you know what's coming and can fail fast when things break.
Honestly, data flow architecture is a game-changer for ML stuff. Your models get fed fresh data constantly instead of waiting around for batch processes to finish - which is super annoying when you need real-time results. Feature engineering happens on the fly, training stays current, and inference is instant. The whole thing scales really well too when you're suddenly dealing with tons of requests. What I love is how event-driven it is. New data comes in, models react immediately. Way better than those overnight batch jobs we used to rely on. I'd look at your current workflows first - see which ones would actually benefit from streaming data before jumping in.
Honestly, your data is probably way messier than you realize - cleaning it for real-time stuff can be brutal. Teams will definitely push back because they're used to batch processing and don't want to learn new things. Stream processing is totally different from the SQL your analysts know, so expect a learning curve there. Oh, and your infrastructure costs might jump at first (that part kinda sucks). Don't try to revolutionize everything overnight though. Pick one small use case, show it actually works, then expand from there. Way less painful that way.
Honestly, data flow architecture is a game changer for governance stuff. You get way better visibility into where your data's actually going - like, you can finally track everything end-to-end. When auditors show up (which they always do), you won't be scrambling to figure out where sensitive data lives. Real-time monitoring catches violations right away instead of finding out months later during those painful reviews. Oh, and you can bake governance rules straight into the flows themselves. Things like retention policies just run automatically. I'd start with your most critical flows first - don't try to boil the ocean.
So basically event-driven architecture is like having smart triggers for your data stuff. When something actually happens - new data drops, user clicks something - boom, your pipeline kicks off automatically. Way better than that annoying "let me check every 5 minutes" thing we used to do. Your flows become super reactive this way. Data gets processed as it streams in instead of just sitting there waiting. Scalability's better too since things only fire up when they need to. Honestly changed how I think about pipeline design - now I always ask what events could trigger each step naturally.
Three main things to nail down: scalability, fault tolerance, and solid data lineage. Your pipelines need to handle traffic spikes without dying, and always build in retry logic plus dead letter queues for when stuff breaks. Trust me, learned that during a brutal Black Friday crash! Monitoring and alerts are clutch - catch problems before they snowball into disasters. Keep transformations idempotent and stateless when you can. Document your schemas obsessively (I know, boring but essential). Start by mapping current data sources and where they're going, then figure out which paths absolutely can't go down.
Dude, visualization tools are a lifesaver - they turn those nightmare data pipeline diagrams into something you can actually read. You'll spot bottlenecks instantly and see exactly where stuff gets stuck. Way better than staring at code all day trying to mentally map like 50 data sources (honestly, who even tries that anymore?). They show real-time flow status and highlight errors. Plus you can drill down into specific transformations when things go sideways. Trust me, when you're troubleshooting at 2am, you'll want the "click here" option instead of digging through logs forever.
-
Use of different colors is good. It's simple and attractive.
-
Excellent Designs.