


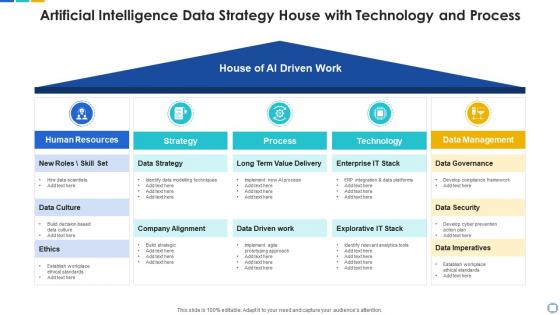
Artificial intelligence data strategy house with technology and process




Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


Our Artificial Intelligence Data Strategy House With Technology And Process are topically designed to provide an attractive backdrop to any subject. Use them to look like a presentation pro.
People who downloaded this PowerPoint presentation also viewed the following :
Artificial intelligence data strategy house with technology and process with all 9 slides:
Use our Artificial Intelligence Data Strategy House With Technology And Process to effectively help you save your valuable time. They are readymade to fit into any presentation structure.
-
Artificial intelligence data strategy house with technology and process
-

Artificial intelligence data strategy house with technology and process
-
Artificial intelligence data strategy house with technology and process
-

Artificial intelligence data strategy house with technology and process
-

Artificial intelligence data strategy house with technology and process
-
Artificial intelligence data strategy house with technology and process
-
Artificial intelligence data strategy house with technology and process
-
Artificial intelligence data strategy house with technology and process
-

Artificial intelligence data strategy house with technology and process
FAQs for Artificial intelligence data strategy house with
Honestly, start by figuring out what data you already have before building anything new. Four things you can't skip: good data governance so people know who owns what, infrastructure that won't crash when you scale up (this is where most projects die, not the fancy algorithms), solid pipelines for cleaning your messy data, and decent privacy/security stuff. Trust me on that last one - it'll come back to haunt you. Make sure whatever you're doing actually ties to business goals though. Don't just hoard data because it seems cool.
Honestly, first thing is figuring out what data you actually have - it's never what you think it is. Check if everything's clean, complete, and accessible. Can your AI tools even read the formats you're using? Also look at whether your team knows how to work with data and if your systems can handle it. The real pain point is usually departments hoarding their own data like dragons. Make a simple spreadsheet listing all your data sources and rate their quality. Don't try fixing everything at once though - just tackle the big wins first. Trust me on this one.
Okay so data governance is basically quality control for your AI stuff. You gotta have clear rules about collecting data, storing it, who can access what - all that boring but necessary compliance stuff. Otherwise your models will suck (garbage in, garbage out, you know?). Honestly, I've seen people skip this step and then spend forever fixing data problems later. Such a pain. Map out what data you actually have first, figure out who owns it, set some basic quality standards. Do this before you get excited about building models. Trust me on this one - it's like building a house without checking if your foundation is solid.
Look at which data sources actually move the needle for your specific AI model first. Quality beats quantity every time - I've seen too many projects crash because people hoarded crappy data thinking more was better. Internal stuff should be your starting point since you can actually control it and won't have compliance headaches. Then add external sources that make sense. Check how fresh the data is, if it's complete, and what it costs to keep updated. Maybe make a quick grid rating each source - business impact on one side, effort to collect on the other. That usually makes the winners pretty obvious.
Track the obvious stuff first - data quality scores, pipeline uptime, model accuracy. But honestly? The business metrics are where you'll actually prove value. ROI on your AI projects, how fast people can get insights, whether decisions are actually getting better. Don't sleep on adoption rates either. I've seen brilliant dashboards that nobody uses because they're too complicated. Pick maybe 4-5 metrics max that connect to your main goals. Oh, and start tracking from day one - trying to create baselines after the fact is such a pain. User satisfaction surveys help too, even if they feel a bit fluffy.
Don't treat data quality like a one-and-done thing - build checks into every step. At ingestion, set up automated rules for catching duplicates, missing values, weird anomalies. Super boring work but you'll thank yourself later. Monitor everything continuously during training and production to catch drift. Version your datasets like you would code so you can roll back when things go sideways. Also track data lineage religiously - always know where your data came from and what's been done to it. Trust me, this stuff will save your butt when models start acting weird.
Look, only grab the data you actually need - don't go crazy collecting everything. Encrypt it when it's moving around and when it's just sitting there. Anonymize personal stuff whenever you can. Honestly? Build privacy protections right into your process from the start, not as an afterthought. Lock down who can access what with proper controls. Oh, and audit regularly - you don't want to be explaining to lawyers why you've got random customer data from like 2019 just chilling in your system. Clear retention policies are your friend here.
Honestly, don't think of structured vs unstructured data as an either/or thing. They work better together anyway. Structured data is your bread and butter - clean, organized, perfect for training models that need consistency. But here's the thing: unstructured stuff like text and images? That's where you find the gold sometimes. Most AI apps that actually work use both. Start with what you're trying to do first, then figure out the mix. Predictive analytics? Go heavy on structured. Computer vision or sentiment analysis? You'll need way more of that messy unstructured data.
Honestly, start with your data pipeline - that's where everything falls apart if you mess it up. Get yourself set up on AWS or Azure first, then add data lakes for storage. Spark's pretty much the go-to for processing these days. You'll need solid ETL tools to actually move your data around without losing your mind. MLOps platforms are total game-changers for deploying models, trust me on that one. Oh, and vector databases are huge now if you're doing anything with embeddings. Don't skip the boring stuff like governance and quality monitoring though - bad data will absolutely wreck your day.
Honestly, just get everyone talking from day one - data engineers, business people, compliance, product teams, the whole crew. Meet regularly about what data you actually have vs what you think you need. I've watched so many projects crash because IT built something completely different from what business wanted! Document everything where teams can all jump in and edit. Figure out who owns what data across departments. Oh and run those cross-team workshops to stay aligned on priorities. Each team needs to get how their work connects to the bigger AI goals.
Honestly, start with consent and transparency - people deserve to know what data you're grabbing and why. Bias is huge too because crappy data creates crappy (and potentially harmful) AI. I learned this the hard way on a project once. Strong privacy protections are non-negotiable, and you'll want to think through potential harm to individuals or groups. The biggest mistake? Trying to add ethics after you've already built everything. Build it in from the beginning, trust me. Way easier than retrofitting later when you're scrambling to fix problems.
Dude, AI is totally changing the data game right now. You're gonna need way more real-time processing power and better quality controls - honestly the storage costs alone are kinda scary. Generative AI especially needs continuous model training, which is completely different from regular analytics stuff. Privacy laws are getting stricter too, so your governance has to be rock solid. I'd audit what you have now and find the gaps. Trust me on this - trying to fix everything later is such a pain and costs like 3x more. Your budget's probably gonna take a hit either way though.
Oh man, the worst thing you can do is hoard data "just in case" - I've watched teams drown in useless stuff. Figure out your AI goals first, then collect backwards from there. Quality beats quantity every time. Also, sort out your data governance right away. Seriously, I know it sounds boring but teams who skip this step? Total nightmare later when they're scrambling to fix privacy and bias issues. Start with something small to test your whole pipeline. Way easier to catch problems early than after you've scaled up and everything's a mess.
So you're gonna need streaming pipelines instead of batch processing - Apache Kafka or AWS Kineus are solid choices for handling the data flow. The real challenge? Making sure your models don't choke on the constant stream or start spitting out weird results. Data validation becomes super critical since you can't manually review everything first. Honestly, I'd start with just one use case and nail that before expanding. Real-time stuff gets messy fast if you try to do too much upfront. Once that first pipeline is bulletproof, then you can think about scaling it out.
Honestly, cloud computing is what makes AI data strategy actually work at scale. You get compute power on-demand for training models, plus storage that expands with your data. No joke - building that stuff in-house is a nightmare and costs a fortune. The best part? You can experiment fast without dropping crazy money upfront. Managed services handle all the annoying pipeline work too. I'd start by moving your data lakes to cloud storage first, then try their ML services. You'll notice the speed difference right away, and everything becomes way more flexible.
-
Easily Editable.
-
Out of the box and creative design.
-
Commendable slides with attractive designs. Extremely pleased with the fact that they are easy to modify. Great work!
-
Excellent products for quick understanding.
-
Helpful product design for delivering presentation.
-
Top Quality presentations that are easily editable.
-
Great designs, really helpful.
-
Qualitative and comprehensive slides.