


Apache Hadoop Powerpoint Presentation Slides






Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


Hadoop is a Java based Apache open-source platform that enables distributed massive datasets among computer clusters using basic programming concepts. Here is a competently designed template on Apache Hadoop that gives a brief idea about the companys current situation through a map and its need in the business. It incorporates templates that depict the importance, global market share, and advantages of Hadoop. In this presentation, we have covered the overview of Hadoop, its different components, Cluster, architecture, its working, and use cases in various sectors. In addition, this Apache PPT contains slides depicting Hadoop as a big data management platform that can be used to jot down the key takeaways. This presentation addresses features of the Apache flume tool for extensive data management in Hadoop. Furthermore, this presentation provides a framework for implementing Hadoop in the company and helps you conduct a comparative analysis between Hadoop 2. x and Hadoop 3. x. Lastly, the deck comprises a 30 60 90 days plan, a roadmap, and a dashboard for Hadoop implementation in the company. Get access now.
People who downloaded this PowerPoint presentation also viewed the following :
Content of this Powerpoint Presentation
Slide 1: This slide introduces Apache Hadoop. State your company name and begin.
Slide 2: This slide states Agenda of the presentation.
Slide 3: This slide shows Table of Content for the presentation.
Slide 4: This is another slide continuing Table of Content for the presentation.
Slide 5: This slide displays title for topics that are to be covered next in the template.
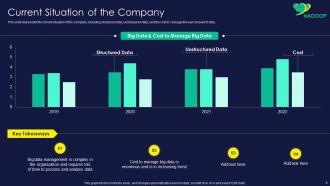
Slide 6: This slide represents current situation of the company, including structured data, unstructured data, etc.
Slide 7: This slide showcases title for topics that are to be covered next in the template.
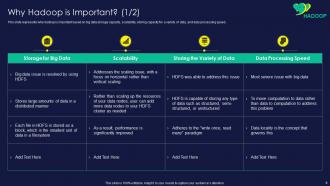
Slide 8: This slide shows why Hadoop is important based on big data storage capacity.
Slide 9: This slide presents importance of the Hadoop Platform, including open-source, Hadoop ecosystem, etc.
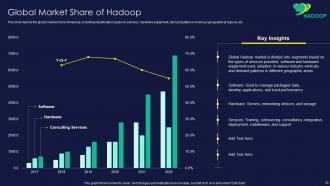
Slide 10: This slide displays global market share of Hadoop, including classification based on services.
Slide 11: This slide represents advantages of Hadoop on the basis of scalability, flexibility, cost, etc.
Slide 12: This slide showcases title for topics that are to be covered next in the template.
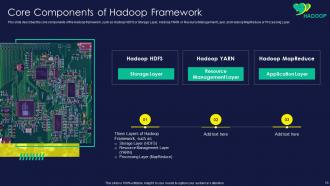
Slide 13: This slide shows Core Components of Hadoop Framework.
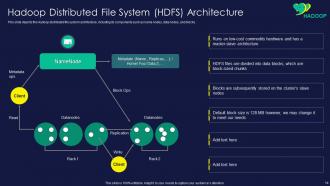
Slide 14: This slide presents Hadoop distributed file system architecture, including its components.
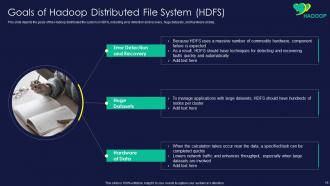
Slide 15: This slide displays Goals of Hadoop Distributed File System (HDFS).
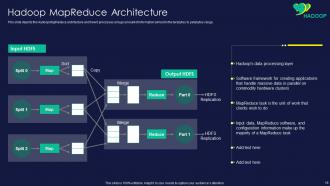
Slide 16: This slide represents Hadoop MapReduce architecture and how it processes a huge amount of information.
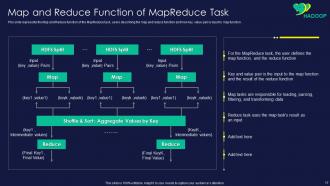
Slide 17: This slide showcases Map and Reduce Function of MapReduce Task.
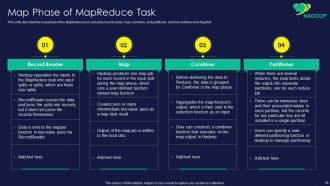
Slide 18: This slide shows map phase of the MapReduce task, including record reader, map, combiner, etc.
Slide 19: This slide presents reduce phase of the MapReduce task that includes the sort and shuffle.
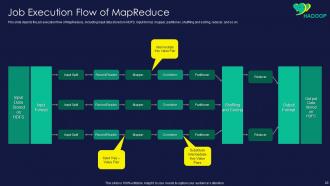
Slide 20: This slide displays job execution flow of MapReduce, including input data stored on HDFS.
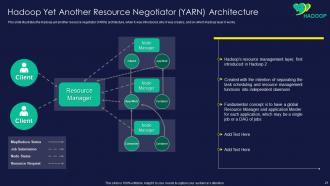
Slide 21: This slide represents Hadoop Yet Another Resource Negotiator (YARN) Architecture.
Slide 22: This slide showcases Components of Yet Another Resource Negotiator (YARN).
Slide 23: This slide shows title for topics that are to be covered next in the template.
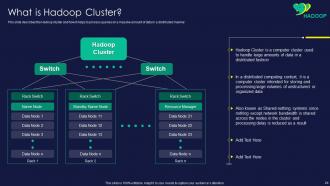
Slide 24: This slide presents Hadoop cluster and how it helps to process queries on a massive amount of data.
Slide 25: This slide displays architecture of the Hadoop cluster’s component.
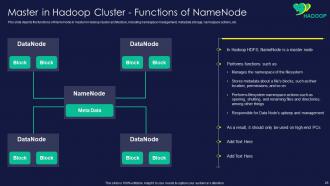
Slide 26: This slide represents functions of Name Node in master in Hadoop cluster architecture.
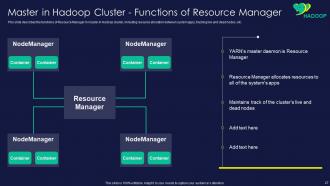
Slide 27: This slide showcases functions of Resource Manager in master in Hadoop cluster.
Slide 28: This slide shows slaves in Hadoop cluster architecture along with functions of its additional components.
Slide 29: This slide presents client node in Hadoop cluster architecture and its various functions.
Slide 30: This slide displays Communication Protocols used in Hadoop Cluster.
Slide 31: This slide represents Best Practices for Building Hadoop Cluster.
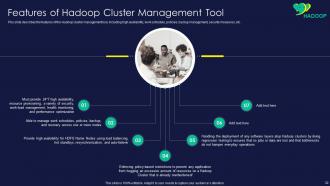
Slide 32: This slide showcases Features of Hadoop Cluster Management Tool.
Slide 33: This slide shows benefits of the Hadoop cluster, including scalable, cost-effective, robustness, etc.
Slide 34: This slide presents title for topics that are to be covered next in the template.
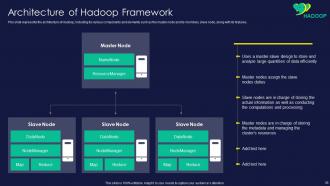
Slide 35: This slide displays architecture of Hadoop, including its various components and elements.
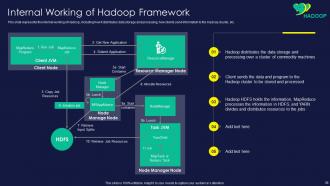
Slide 36: This slide represents internal working of Hadoop, including how it distributes data storage and processing.
Slide 37: This slide showcases Operation Modes of Hadoop Framework.
Slide 38: This slide shows title for topics that are to be covered next in the template.
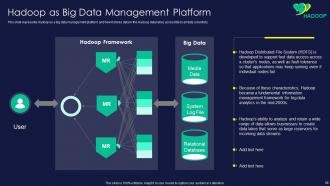
Slide 39: This slide presents Hadoop as a big data management platform and how it stores data in the Hadoop data lakes.
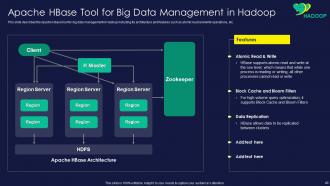
Slide 40: This slide displays Apache HBase Tool for Big Data Management in Hadoop.
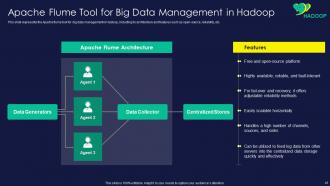
Slide 41: This slide represents Apache Flume Tool for Big Data Management in Hadoop.
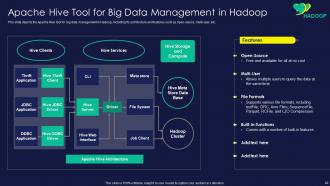
Slide 42: This slide showcases Apache Hive Tool for Big Data Management in Hadoop.
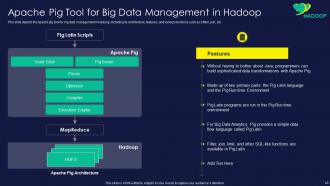
Slide 43: This slide shows Apache Pig Tool for Big Data Management in Hadoop.
Slide 44: This slide presents title for topics that are to be covered next in the template.
Slide 45: This slide displays checklist to implement the Hadoop framework in the organization.
Slide 46: This slide represents Deployment of Hadoop Framework in Company.
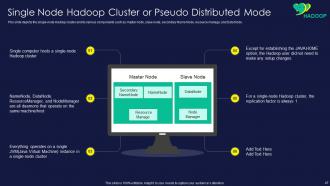
Slide 47: This slide showcases Single Node Hadoop Cluster or Pseudo Distributed Mode.
Slide 48: This slide shows Multi Node Hadoop Cluster or Fully Distributed Mode.
Slide 49: This slide presents methods to get data into the Hadoop framework.
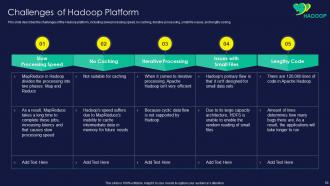
Slide 50: This slide displays challenges of the Hadoop platform, including slow processing speed, no caching, etc.
Slide 51: This slide represents solutions to Hadoop challenges such as Spark, Flink, Hadoop Archives, etc.
Slide 52: This slide showcases title for topics that are to be covered next in the template.
Slide 53: This slide shows Comparison between Hadoop 2.x and Hadoop 3.x.
Slide 54: This slide presents comparison between Hadoop and Spark based on factors such as performance, cost, etc.
Slide 55: This slide displays title for topics that are to be covered next in the template.
Slide 56: This slide represents impacts of Hadoop on businesses, including big data analysis and queries.
Slide 57: This slide showcases impacts of Hadoop on the business, including data-driven decisions, better data access, etc.
Slide 58: This slide shows title for topics that are to be covered next in the template.
Slide 59: This slide presents 30-60-90 Days Plan for Hadoop Implementation.
Slide 60: This slide displays title for topics that are to be covered next in the template.
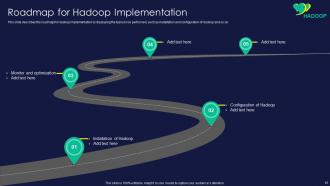
Slide 61: This slide represents roadmap for Hadoop implementation by displaying the tasks to be performed.
Slide 62: This slide showcases title for topics that are to be covered next in the template.
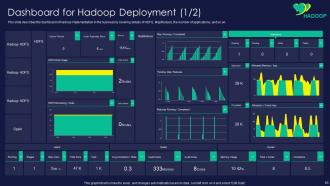
Slide 63: This slide shows dashboard of Hadoop implementation in the business by covering details of HDFS.
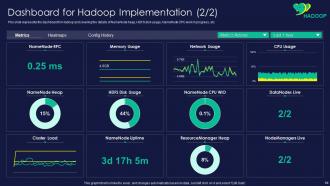
Slide 64: This slide presents dashboard for Hadoop and covering the details of NameNode heap, HDFS disk usage, etc.
Slide 65: This slide is titled as Additional Slides for moving forward.
Slide 66: This slide represents title for topics that are to be covered next in the template.
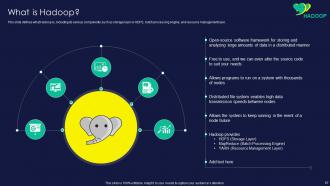
Slide 67: This slide shows what Hadoop is, including its various components such as storage layer or HDFS, batch processing engine, etc.
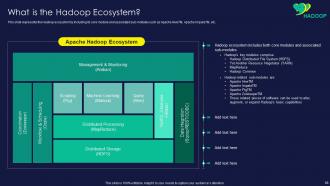
Slide 68: This slide presents Hadoop ecosystem by including its core module and associated sub-modules.
Slide 69: This slide displays disadvantages of Hadoop on the basis of security, vulnerability by design, etc.
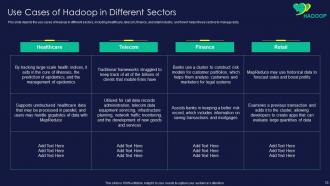
Slide 70: This slide represents use cases of Hadoop in different sectors, including healthcare, telecom, finance, etc.
Slide 71: This slide contains all the icons used in this presentation.
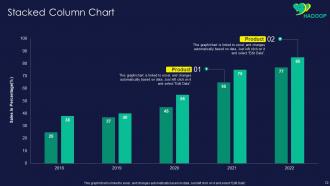
Slide 72: This slide represents Stacked Column chart with two products comparison.
Slide 73: This is Our Goal slide. State your firm's goals here.
Slide 74: This is an Idea Generation slide to state a new idea or highlight information, specifications etc.
Slide 75: This slide depicts Venn diagram with text boxes.
Slide 76: This slide shows Post It Notes. Post your important notes here.
Slide 77: This slide contains Puzzle with related icons and text.
Slide 78: This is a Comparison slide to state comparison between commodities, entities etc.
Slide 79: This is a Thank You slide with address, contact numbers and email address.
Apache Hadoop Powerpoint Presentation Slides with all 84 slides:
Use our Apache Hadoop Powerpoint Presentation Slides to effectively help you save your valuable time. They are readymade to fit into any presentation structure.















































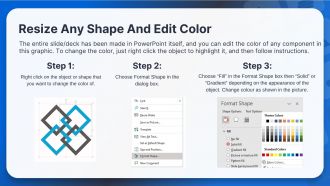
FAQs for Apache Hadoop
So Hadoop's got four main parts you need to know about. HDFS handles storage by splitting your data across multiple machines. YARN manages resources and schedules jobs. Then there's MapReduce for processing, though honestly most people just use Spark now - way faster. Hadoop Common is basically the shared libraries that make everything work together. The cool thing about YARN is you can run different processing engines on the same HDFS data, so you're not stuck with just one option. I'd focus on HDFS and YARN first since those are really the foundation of everything else.
So basically HDFS makes 3 copies of everything automatically across different machines. When stuff breaks (which happens way more than you'd think), you've still got backups running elsewhere. The NameNode keeps track of where everything lives and spins up new copies if something dies. It also runs health checks to catch corrupted data early. You just set how many copies you want and forget about it - honestly the whole thing runs itself. Way better than manually backing everything up like we used to do.
So MapReduce is Hadoop's thing for handling huge datasets - it splits everything into smaller pieces that different machines can work on at the same time. Two main steps: Map breaks up your data and processes chunks across nodes, then Reduce pulls it all back together. Picture sorting a mountain of paperwork by giving everyone their own stack to handle (way faster than doing it yourself). Yeah, Spark's the hot thing now, but MapReduce still does the job for batch processing when you're not racing against the clock. Pretty straightforward once you get it.
So basically Hadoop 1.x was kind of a mess - JobTracker and TaskTracker tried to do everything at once, handling both resources and job scheduling in one bloated system. Then 2.x came along with YARN, which finally split things up properly. You've got ResourceManager dealing with cluster stuff, NodeManager for individual nodes, and ApplicationMaster for specific jobs. Way cleaner setup. Plus you can actually run other workloads besides MapReduce now, which is pretty cool. Honestly, if you're building something new, just skip straight to 2.x - the old architecture will drive you nuts.
Dude, if you're dealing with tons of data, Hadoop's actually pretty solid. It scales horizontally - just throw more cheap servers at it instead of buying some crazy expensive machine. Works with messy, unstructured stuff too, which honestly saves your butt when real-world data is all over the place. Built-in fault tolerance means one server crashing won't kill everything. Traditional systems? They hit a wall fast when data grows. I'd say once you're looking at terabytes, it's worth checking out - though the learning curve can be annoying at first.
Oh man, data locality is everything for Hadoop performance. Your jobs will crawl if data keeps getting shuffled across the network instead of processing locally. The scheduler usually does decent work placing tasks near their data, but honestly it's not perfect - especially if you're running a tiny cluster. I/O heavy jobs get hit the worst when you're moving massive datasets around. Keep your block sizes reasonable (not too small or you'll fragment everything) and make sure data spreads evenly across nodes. Trust me, you'll notice the difference immediately.
Honestly, Hadoop shows up in way more places than you'd think. Banks use it for fraud detection - makes sense when you're processing millions of transactions daily. Healthcare companies are all over it for patient analytics and drug research. Retail giants like Amazon? They're using it to figure out what you'll buy next (kinda creepy but whatever). Telecom uses it for call patterns and network stuff. Manufacturing loves it for predicting when machines will break down. Really, any company drowning in messy data that can't afford fancy alternatives should check it out. If you've got terabytes of random data sitting around, it's probably worth a look.
So Hadoop works with Hive and Pig as these layers that sit on top of the main system. With Hive, you can write SQL-like queries instead of dealing with complicated Java code - saves a ton of headaches. Pig's got its own thing called Pig Latin for transforming data. Both translate whatever you write into MapReduce jobs that just run automatically. Perfect for analysts who'd rather not code in Java all the time (and honestly, who can blame them?). I'd start with Hive since it's SQL-based. Way easier if you already know database stuff.
So Hadoop's got pretty decent security once you set it up right. Kerberos handles user authentication, and HDFS permissions work just like Unix file permissions. Data gets encrypted whether it's stored or moving around. Ranger manages authorization policies across everything - took me forever to figure that one out but it's solid. YARN keeps different workloads separated too. Oh, and here's the kicker - none of this security stuff is turned on by default. You've gotta manually configure it all when you're setting up your cluster, which honestly seems backwards to me.
Honestly, you're gonna deal with hardware failures constantly - something's always broken when you've got hundreds of nodes. Data skew is brutal too, makes debugging a total pain when everything's unevenly distributed. Resource allocation becomes this whole mess because Hadoop's utilization is all over the place. Adding new nodes sounds simple but keeping things balanced? Way harder than expected. Oh, and capacity planning - good luck with that one. My suggestion: start small and monitor like crazy. Spend the extra time getting your cluster config right from day one. Trust me, it beats those lovely 2am emergency calls.
Dude, start by checking your cluster config - bump up memory allocation and tweak mapper/reducer counts for better parallelism. Honestly, file formats make a huge difference too, so ditch plain text for Parquet or ORC if you can. Data locality is everything though. I've literally watched jobs go 3x faster just from smart partitioning alone. Compression helps too, obviously. Oh and definitely profile your jobs first - you'd be surprised where the actual bottlenecks are hiding. Monitor your current metrics before changing anything major so you know what's actually slow.
So YARN handles resource management for Hadoop clusters - divides up CPU and memory between jobs. Before it existed, you could only run MapReduce which was pretty limiting. Now you can throw Spark, Storm, whatever at the same cluster without everything crashing into each other. It's like having a bouncer that keeps different frameworks from fighting over resources. Honestly makes multi-framework setups way less painful. The scheduler part is actually pretty clever about maximizing what you've got. If you're doing anything beyond basic MapReduce, you'll definitely want to get how YARN allocates stuff or you'll be troubleshooting weird conflicts later.
Batch your data instead of streaming single records - way more efficient that way. Sqoop works great for database stuff, Flume handles log files, and Kafka's solid for real-time streams. Definitely compress everything during transfer. Saves you tons of bandwidth and storage costs. Partition logically too - by date or region makes sense. One thing I learned the hard way: validate data quality right at ingestion. Finding problems later is such a pain. Oh, and start with a small pilot dataset first before you go crazy with scaling. Trust me on that one!
So basically, Hadoop is like the backbone for ML and real-time analytics. You dump all your massive datasets there since regular systems would just die. Spark runs right on top of it - super convenient for training models on insane amounts of data. For the real-time piece, stuff like Kafka and Storm plug into Hadoop pretty nicely. They'll process your streaming data while keeping all the historical stuff stored for comparisons. Honestly took me forever to wrap my head around it at first. But once you've got your data lake sorted in HDFS, everything else clicks into place. The distributed computing power is really what makes it all work.
Hey! So first thing - get on their dev mailing lists and browse JIRA for open issues. Start small though, like a bug fix or docs update to learn their process. They use GitHub PRs or you can attach patches directly to JIRA tickets. Read their contributor guidelines and follow their coding style (obviously). Tests are mandatory - they're pretty strict about unit test coverage. The community's actually really friendly to new people, which honestly surprised me at first. Once you get the hang of their workflow, then you can jump into bigger features.
-
The PPTs are extremely simple to modify. Thank you for providing the slides that are ready to be used. They assist me in saving a lot of time.
-
I looked at their huge selection of themes and designs. They appeared to be ideal for my profession. I'm sure I'll grab a few of them.