


Big Data Engineer Powerpoint Presentation Slides





Try Before you Buy Download Free Sample Product
 Impress Your
Impress Your Audience
Editable
of Time


Big Data is a massive collection of data that continues to increase dramatically over time. It is a data set that is so vast and complicated that no standard data management technologies can effectively hold or handle it. Here is a competently designed template on Big Data Engineer that provides details about the problems experienced by organizations to manage big data along with their solutions. It further highlights the top sources of big data, architecture, and workflow of extensive data management. This presentation covers sections for the different types of data, multiple resources of big data, working of big data, technologies, etc. It also comes with a ready made checklist for big data management. Additionally, this PPT talks about the impacts of extensive data management on business processes and their benefits. Furthermore, this template includes a training program for comprehensive data management, budget planning, and big data applications in different sectors such as healthcare, education, automobile, finance, etc. Also, this PPT provides a 30 60 90 days plan and a roadmap for extensive data management. Lastly, this deck comprises a dashboard for comprehensive data management. Download the template now.
People who downloaded this PowerPoint presentation also viewed the following :
Content of this Powerpoint Presentation
Slide 1: This slide displays the title Big Data Engineer.
Slide 2: This slide displays the Agenda for Big Data Engineer.
Slide 3: This slide exhibit table of content.
Slide 4: This slide exhibit table of content- Overview of Big Data Service Provider Company.
Slide 5: This slide represents the overview of the big data company.
Slide 6: This slide exhibit table of content- Business Solutions we Provide for Big Data Management Problems.
Slide 7: This slide represents one challenge of big data that is lack of knowledge and professionals.
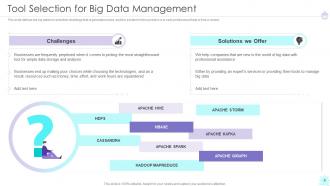
Slide 8: This slide defines the big data tool selection challenge that organizations face.
Slide 9: This slide explains another challenge that is paying loads of money on hardware, new hires, software development, and its solution.
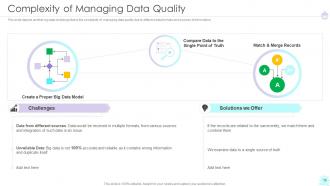
Slide 10: This slide depicts another big data challenge that is the complexity of managing data quality due to different data formats and sources of information.
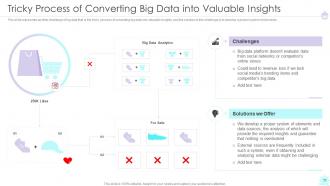
Slide 11: This slide represents another challenge that is the tricky process of converting big data into valuable insights.
Slide 12: This slide represents the securing information in big data challenge of big data and solutions to this challenge.
Slide 13: This slide exhibit table of content- Let’s Discuss Big Data and Its Types.
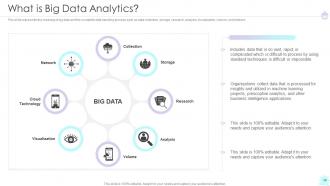
Slide 14: This slide represents the meaning of big data analyticsand the complete data handling process.
Slide 15: This slide describes the top sources of big data collection such as media data, cloud data, web data.
Slide 16: This slide represents the most critical Vs of big data such as volume, variety, value, and variability and how they work.
Slide 17: This slide depicts the importance of big data and how collected data will help organizations.
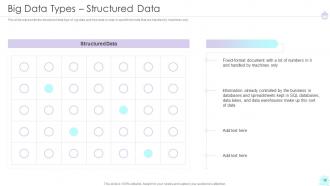
Slide 18: This slide represents the structured data type of big data and how data is kept in specific formats that are handled by machines only.
Slide 19: This slide depicts the unstructured data form of big data.
Slide 20: This slide represents the semi-structured data form of big data.
Slide 21: This slide exhibit table of content- Architecture and Workflow after Big Data Management.
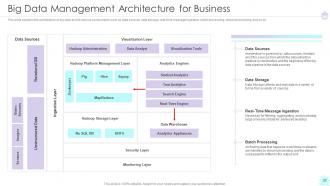
Slide 22: This slide explains the architecture of big data and its various components.
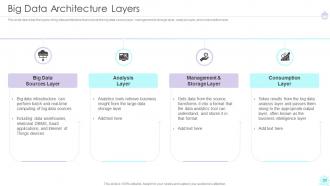
Slide 23: This slide describes the layers of big data architecture.
Slide 24: This slide depicts the processes of big data architecture.
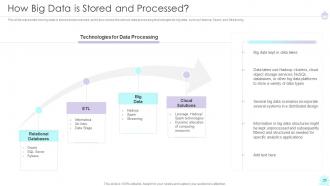
Slide 25: This slide represents how big data is stored and processed.
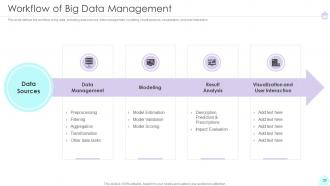
Slide 26: This slide defines the workflow of big data, including data sources, data management, visualization, and user interaction.
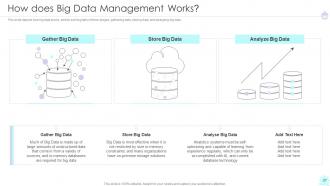
Slide 27: This slide depicts how big data works, and its working falls in three stages: gathering data, storing data, and analyzing big data.
Slide 28: This slide exhibit table of content- Technologies and Strategies we Offer for Big Data Management.
Slide 29: This slide represents the leading big data management technologies.
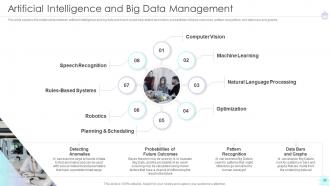
Slide 30: This slide explains the relationship between artificial intelligence and big data.
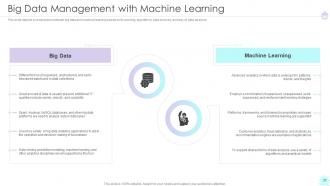
Slide 31: This slide depicts a comparison between big data and machine learning based on its working, algorithms, data sources.
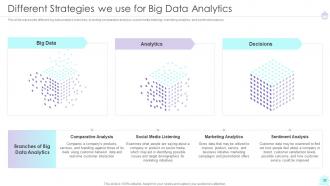
Slide 32: This slide represents Different Strategies we use for Big Data Analytics.
Slide 33: This slide exhibit table of content- Impacts and Benefits after Big Data Management.
Slide 34: This slide explains the checklist for big data strategy.
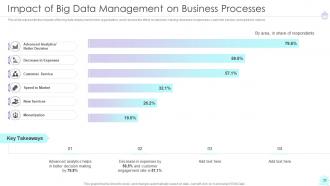
Slide 35: This slide represents the Impact of Big Data Management on Business Processes.
Slide 36: This slide represents the Benefits of Big Data Management for Business.
Slide 37: This slide exhibit table of content- Training and Budget for Big Data Management.
Slide 38: This slide represents the training program for big data management.
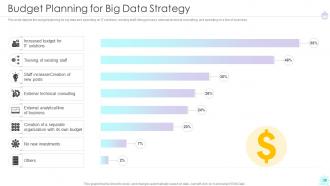
Slide 39: This slide depicts the budget planning for big data strategy.
Slide 40: This slide exhibit table of content- Different Industries in Which we Manage Big Data.
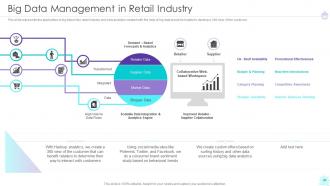
Slide 41: This slide represents the application of big data in the retail industry.
Slide 42: This slide represents the application of big data in the healthcare department.
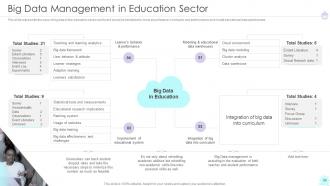
Slide 43: This slide represents the uses of big data in the education sector.
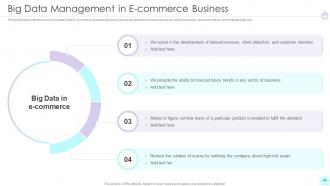
Slide 44: This slide represents the uses of big data in the E-commerce business.
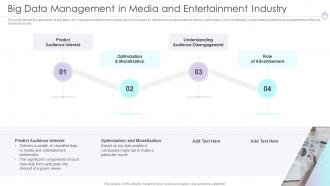
Slide 45: This slide depicts the application of big data in the media and entertainment industry.
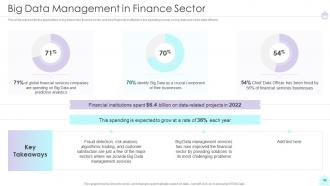
Slide 46: This slide represents the application of big data in the finance sector.
Slide 47: This slide depicts the uses of big data in the travel industry.
Slide 48: This slide represents the big data application in telecommunication.
Slide 49: This slide explains the big data use cases in the automobile industry.
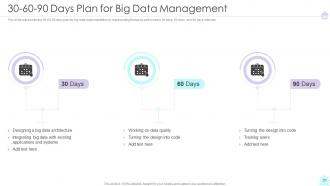
Slide 50: This slide exhibit table of content- 30-60-90 Days Plan for Big Data Management.
Slide 51: This slide represents the 30-60-90 days plan for big data implementation.
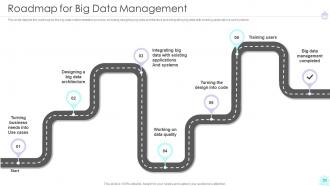
Slide 52: This slide exhibit table of content- Roadmap for Big Data Management.
Slide 53: This slide exhibit table of content- Roadmap for Big Data Management.
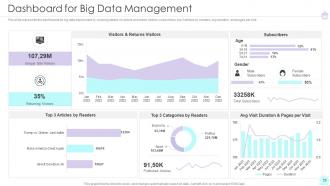
Slide 54: This slide exhibit table of content- Dashboard for Big Data Management.
Slide 55: This slide represents the dashboards for big data deployment.
Slide 56: This is the icons slide.
Slide 57: This slide presents title for additional slides.
Slide 58: This slide presents your company's vision, mission and goals.
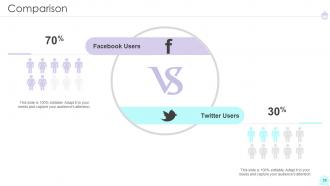
Slide 59: This slide presents Comparison of Facebook Users and Twitter Users.
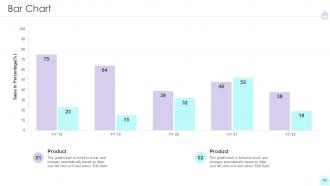
Slide 60: This slide displays yearly bar graph for different products.
Slide 61: This slide exhibits ideas generated.
Slide 62: This slide displays puzzle.
Slide 63: This slide shows roadmap.
Slide 64: This slide shows Mind Map.
Slide 65: This is thank you slide & contains contact details of company like office address, phone no., etc.
Big Data Engineer Powerpoint Presentation Slides with all 70 slides:
Use our Big Data Engineer Powerpoint Presentation Slides to effectively help you save your valuable time. They are readymade to fit into any presentation structure.





































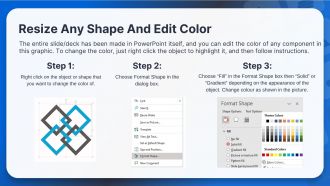
FAQs for Big Data Engineer
You're basically building all the behind-the-scenes stuff that makes data actually work. Think data pipelines, storage systems, making sure everything flows from random sources into something useful. Performance optimization is huge too - slow dashboards are the worst. Security's obviously part of it, plus you'll work with data scientists and analysts constantly. Honestly, the variety keeps it interesting. Cloud platforms are pretty much mandatory now, and tools like Spark or Kafka will be your best friends. It's one of those roles where you're always learning something new.
Honestly, it's all about what gets you excited. Big Data Engineers build the pipes and systems that move data around - you're designing databases, creating data flows, basically the infrastructure stuff. Data Scientists take that clean data and run stats models or ML algorithms to find patterns. That plumber analogy is pretty bad but whatever, it kinda works lol. Engineers are more on the technical architecture side, scientists are doing the actual analysis and hypothesis testing. I'd say go engineering if you like solving system problems and building things that scale. Data science if you're into the math-y research side of figuring out what the data actually means.
Definitely start with Python and SQL - that's your bread and butter right there. Python works with basically everything (pandas, Spark, all the good stuff) and SQL is just unavoidable for databases. Java or Scala matter too since most big data tools run on JVM. Scala's honestly kind of annoying to learn but pays off for Spark performance later. R might be useful if you're constantly working with data scientists, though I wouldn't stress about it initially. My advice? Get solid with Python and SQL first, then see what your team actually uses before diving into Java or Scala.
So data warehousing is where you take all that processed data and organize it so analysts can actually run reports without wanting to scream. You'll design schemas and build ETL pipelines to move stuff from raw storage into the warehouse. Think of it like being a librarian but for massive datasets - everything has to be catalogued right or people can't find anything. Performance matters too because slow queries = angry analysts. Tools like Snowflake, Redshift, BigQuery are your main weapons. Oh and learn dimensional modeling early - trust me, it'll save you tons of pain later when things get complex.
Honestly, start with Spark and Python - that combo will get you pretty far. Hadoop's still foundational stuff you gotta know. SQL is everywhere so get solid with that across different databases. For streaming, Kafka's huge right now. Cloud platforms are unavoidable these days (AWS, GCP, Azure - just pick one and go deep). Airflow's clutch for orchestration. Docker and Kubernetes are becoming standard too, which is kinda annoying but whatever. My take? Master Spark and Python first, then branch out. Those two skills open tons of doors.
Honestly, you gotta catch this stuff early with automated checks at your ingestion points - schema validation, data profiling, anomaly detection. The whole nine yards. I've watched so many teams skip this part and then pull their hair out when garbage data tanks everything downstream. Build quality checks right into your ETL instead of slapping them on later. Also grab some data lineage tracking so you can actually trace back where things went sideways. Trust me on this one - fixing it upfront beats playing detective with corrupted pipelines later.
Dude, unstructured data is such a pain. You've got tons of text, images, videos just sitting there with zero organization - nothing fits into normal databases. Processing it all? Nightmare fuel. The schemas get messy fast since there's no standard format, and you need fancy NLP stuff that eats up computing power like crazy. Oh and don't get me started on data quality - it's inconsistent garbage half the time. Performance tanks when you're digging through terabytes of random stuff. Honestly though, pick one small project first. Get a decent data lake setup and solid preprocessing going before you tackle anything bigger.
Dude, cloud computing totally changed everything for big data work. Instead of waiting forever for new hardware, you just spin up whatever you need on AWS, Google Cloud, Azure - whatever. Way less time dealing with servers, way more time actually building cool stuff. The experimentation part is huge too since you can test different tools without buying anything first. Honestly feels like cheating sometimes compared to how things used to be. Oh and definitely pick one platform to really dive deep into - I'd probably go AWS since it's everywhere, but that's just me. Makes you way more valuable.
Honestly, SQL optimization is where I'd start - efficient queries and understanding execution plans will save you so much headache. Get comfortable with Python or Scala for Spark too. But here's the thing - most people just throw hardware at slow pipelines instead of actually figuring out what's wrong first. Bad move. Airflow or Prefect are solid for orchestration, and you'll need monitoring tools to catch performance issues. Oh, and definitely audit what you have now. Find your slowest steps and fix those before anything else. Half this job is just knowing your data patterns anyway.
Data scientists are probably your biggest collaboration - you're building all the pipelines for their models and making sure their data doesn't suck. DevOps is constant coordination since they deploy your stuff while you handle the actual data engineering like ETL and storage. Product teams need you to figure out what data they actually want (which changes weekly, obviously). The boundaries get pretty blurry though. Everyone's working in the same cloud environment anyway. Main thing is setting up clear handoffs so people aren't duplicating work or breaking each other's code.
Honestly, just collect what you actually need - don't go overboard with data hoarding. Get proper consent first, especially with GDPR and those privacy laws floating around. Here's the thing though: anonymizing data is way harder than people think. Datasets get combined and suddenly your "anonymous" info isn't so anonymous anymore. Security controls for storage are obviously crucial, and you gotta be upfront about what you're doing with people's info. Oh, and audit your practices regularly - like, really ask yourself if this could screw someone over. Better safe than sorry with this stuff.
ML can automate all that tedious pattern detection and anomaly stuff you're probably doing by hand right now. Train models to classify your incoming data or predict missing values instead of writing those endless rule-based scripts. The coolest part? Models can actually predict when your clusters need more resources based on usage patterns. Honestly, dynamic scaling alone makes this worth exploring. Don't go crazy though - just pick one manual validation task you're sick of doing and build a simple classifier around it. Baby steps work better than trying to ML-ify everything at once.
Honestly, streaming analytics and cloud-native stuff are taking over everything right now. Batch processing is basically dead - everyone wants real-time data flowing through event-driven systems. AI/ML integration isn't optional anymore, it's just part of the pipeline. DataOps is actually pretty cool though, treating data infrastructure like regular software with proper CI/CD. Serverless makes scaling way less painful too. My advice? Get familiar with Kafka and whatever cloud platform your company uses. That's where the good jobs are going, and frankly, it's more interesting work than dealing with old batch systems anyway.
Honestly, you're basically the person who makes sure data actually works for everyone else. So you'll build pipelines that grab messy raw data and turn it into something analysts can use without crying. Performance optimization is huge too - nobody wants to wait 3 hours for a simple report. I've seen teams fall apart over slow queries, it's brutal. You also set up quality checks so the data isn't total garbage. Oh and governance stuff, which sounds boring but prevents chaos later. Really though, it's all about building systems that don't break and deliver clean data fast.
So basically you're dealing with encryption everywhere - data at rest, in transit, all that stuff. Role-based access controls are huge too. I spend most of my time setting up frameworks like Apache Ranger or AWS IAM so only the right people can touch specific data. Data masking for anything sensitive is a must. Compliance docs are honestly such a pain but you can't skip them. Audit trails and data lineage tracking help a ton though. Oh, and don't forget regular security scans - they catch stuff you'd miss otherwise. Pro tip: build all this security into your pipelines from the start. Trying to add it later? Yeah, that's a special kind of hell you don't want to experience.
-
“I required a slide for a board meeting and was so satisfied with the final result !! So much went into designing the slide and the communication was amazing! Can’t wait to have my next slide!”
-
“The presentation template I got from you was a very useful one.My presentation went very well and the comments were positive.Thank you for the support. Kudos to the team!”